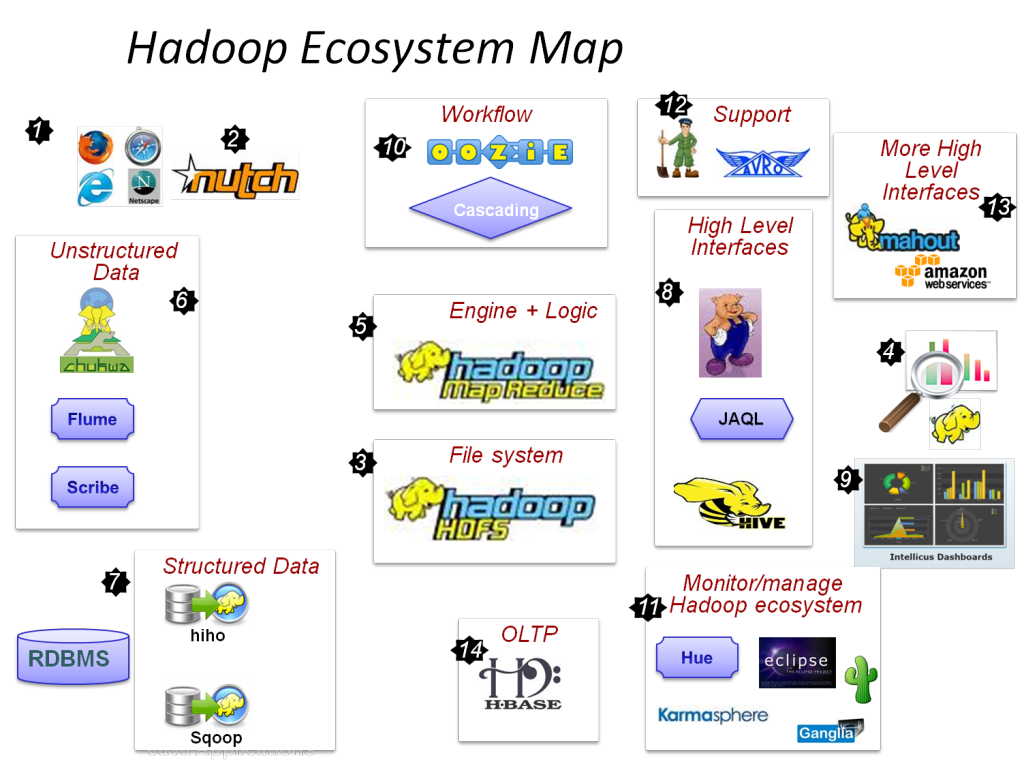
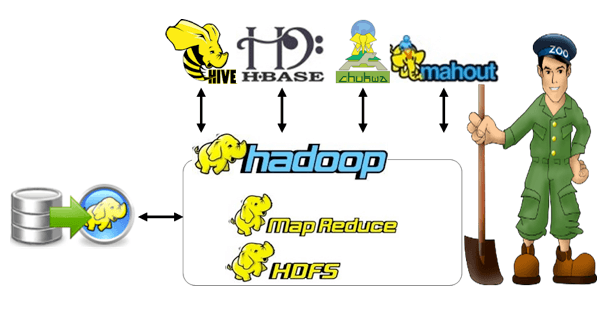
Hadoop Project Topics
Hadoop Project Topics give tons of fuel for you to undertake highly challengeable research to attain the great and grand zenith in your research profession. Our Universal Top Graded institution launched for the reason of improves all-encompassing students and research academicians. Our world’s top Hadoop experts develop our organization as a Globe 1st Sill Development Stadium by our innovative and ingenious knowledge. We make highly talented and skilful engineers by our best training solutions and software development programs. Today, we conducting our IT development and training programs in various colleagues and universities. Successful people will do simple things differently, you are one of them, ring us for your success. Do you want to know more information about our unique service? You can connect with us by dint of our live chat support.
Hadoop Project Topics
Hadoop Project Topics provide most excellent and breaking new ground project topic for students and research scholars to pick the top standardized topic with the help of our certified Hadoop professionals. We are experts in Hadoop development which allows for large data set distributed processing using single programming approaches across clusters of computers. We grant the best knowledge in Hadoop implementation, algorithms, technologies, tools and software etc.
Unique Opportunities for Hadoop:
- Cloud storage is dependable and cheap over Hadoop
- Pay for data processing alone that you need
- Scale Rapidly and Optimize Operations
- Test new processes inexpensively and quickly
In today’s digital age, designing or creating advances in data intelligence over Hadoop is a challenging issue to a successful upcoming business enterprise. Let’s see about Caserta,
Caserta is an innovative solution that integrated on cloud to do all things data. It is established for Big Data ecosystem implementations and development. On 2016, it awarded and included to top 20 big data tools.
About Caserta Concepts:
- Data on the Cloud Framework
- Data Visualization and Interaction
- Data Analytics and Data Science
- Business Intelligence
- Big Data Analytics
- Data Warehousing
Upcoming events on Caserta:
- Text analytics on Social Network Data
- Big Data Governance Toolkit
- Search based Business Intelligence (BI)
- End-to-end streaming/ Continuous Integration
- Recommendation Engine Optimization
- NLP on Search based BI
- DevOps for Analytics
- Artificial Intelligence (AI)
- Virtual Assistance BI (Voice)
- Virtual Reality BI (VR)
- Predictions/Reporting Converge
Cloud Components are support for Caserta Concepts that are follows:
-Scalable Distributed Storage
- AWS [S3]
- Google [GCS]
- Microsoft [Azure Storage]
-Compute Services
- AWS [EC2]
- Google [GCE]
- Microsoft [VMs]
-Data Streaming
- AWS [Jupyter]
- Google [DataLab]
- Microsoft [Azure Notebook]
-Consistent Extensible Framework
- AWS [Spark]
- Google [Spark]
- Microsoft [spark]
–Common Interface
- AWS [Jupyter]
- Google [DataLab]
- Microsoft [Azure Notebook]
-Pluggable fit for purpose processing
- AWS [EMR]
- Google [DataProc]
- Microsoft [HD Insight]
-Dimensional MPP Data Warehouse
- AWS [Redshift]
- Google [BigQuery]
- Microsoft [Azure SQL DataWarehouse]
Nowadays, we work on the following Hadoop Project Topics:
- Prototype Development of Virtual Datacenter for Parallel and Distributed Big Data Processing Using Hadoop Framework
- Implemented Proactive Node Management and Analyze Network Using an Innovative Scheme in Hadoop Paradigm
- ELRAS (Efficient Locality and Replica Aware Scheduling) Scheme Based Heterogeneous Clustering Using Improvement of MapReduce Performance
- Enrich Hadoop Processing Tool “Hive” Security with VMWARE Framework Using Mechanism Design
- Concept Drift Identification and Prediction Using Parallel Dynamic Data Driven Approach
- Toward Distributed Machine Learning Using Dynamically Partitioning Scheme in Shared Clusters
- Reinforcement Learning Using a Novel Scheduling Scheme for Heterogeneous Distributed Framework
- 3D (Three Dimensional) Ranging Point Clouds Gridding and Light Detection Using high Performance Parallel Approaches
- Bid Database and Low Latency System and Browser for Three Dimensional Genomic Data Querying, Storage and Visualization
- Data Structure for Designing and Planning Based Heterogeneous HPC Systems Workload Management
- Evaluate BM Based String Matching Algorithms Performance in Distributed Computing Paradigm
- Distributed Frameworks and Hadoop Clusters Using Infrastructure of Light Weight Cloud Based Virtual Computing
- Cloud Applications Adaptive Profiling Using Decision Tree Based Approach
- Tread Local Streams for Real Time Applications in Distributed Streaming
- Big Heterogeneous Data Parallel Processing for Internet of Things Network Security Monitoring