Hadoop Based Projects
Hadoop Based Projects give the lush knowledgeable land for you to reap your fruit of success today and always. Our group of certified brilliants introduces predominance of services for universal ubiquitous of students and research philosophers to enhance their knowledge in Hadoop Based projects. We offer immense of training for students and research colleagues including design and implement projects, prepare project documentation/ thesis, prepare journal paper/conference paper, journal publication support etc. Today, we are members in world’s top journals. Owing to, we recently support thousands of scholars to prepare and publish their journals on top journals. Do you need our support on journal paper preparation/publication? Ring us instantly. The starting point of all achievement is desire. Your enthusiasm will inspire us to move forward with actions that bring rewarding achievements………..
Hadoop Based Projects
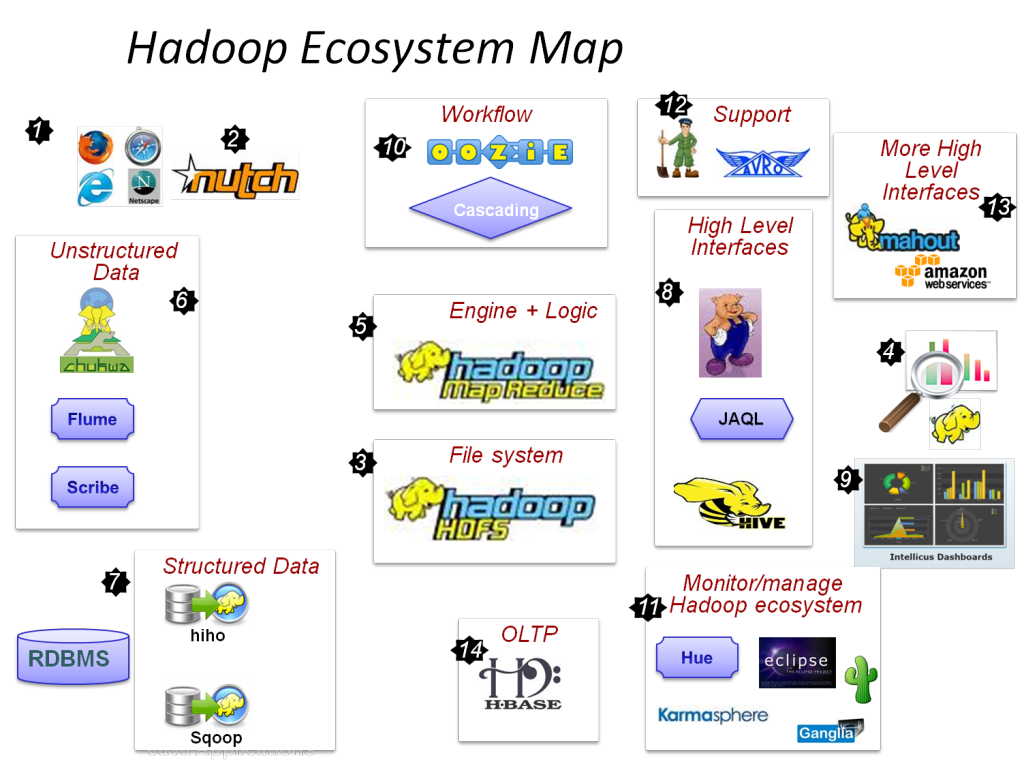
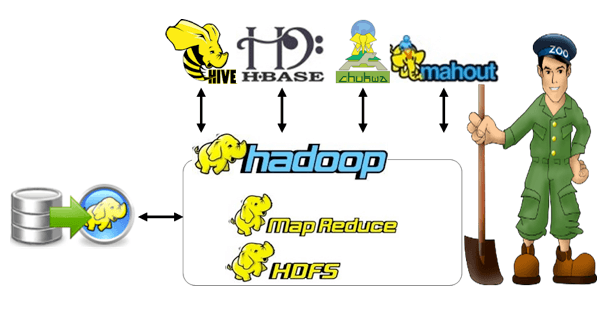
Hadoop Based Projects offer miraculous intellectual platform for you to start your successful moments. Our Hadoop Based Projects service organizes with the hope of grant wide range of fabulous Hadoop training for students and research academicians to make you as a record-breaking expert. We give our training in MapReduce, Oozie, Sqoop, Flume, YARN, HBase, Hive, HDFS (Hadoop Distributed File System) and Pig for you to develop advanced Hadoop Based Projects by own.
Simple Steps to run Hadoop based Projects:
- Initially setup Hadoop Environment by instructions available in online
- Install hive or pig for comfort programming
- Copy the large dataset into HDFS storage system which you need for your applications
- Open JAVA/Pig/Hive for programming
- Now write a script or query based on your requirement
The Nine Hadoop Based Projects Tagged in Hadoop:
- HadoopStudio (MapReduce Development Environment compatible with Netbeans)
- Gfarm (Distributed File System for Large Scale Cluster Computing)
- Beanstalker (Set of Maven Plugins for Amazon Web Services)
- Hypertable (Scalable and high performance database)
- Syoncloud Logs (Processes log files from various applications)
- MapReduce-BitDew (Execute MapReduce applications)
- Dispy (Parallel execution of computations)
- Telepath (Processing Wikipedia pagecounts using MapReduce code)
- Infovore (processing large RDF datasets on MapReduce framework)
Our Ongoing Evolution on Hadoop:
- Hadoop Vs. Spark performance comparison on both standalone service and big data applications
- Enable Hadoop Clusters without using MapReduce and HDFS
- Design New SQL-on Hadoop Tools
- Mixing Hadoop with other big data frameworks
- Hadoop should addresses some maturity challenges
- Searching of Unknown unknowns over Open Lucene Search Engine and Hadoop
- Yarn-Storm pairing on Hadoop
- Hadoop Development Tools (HDT) consider for Higher level tasks
There is a list of topics based on Hadoop Based Projects, in that you can pick your topic related to Hadoop and we provide complete support to implement your final year or research based projects from your own ideas.
- Effectual Guaging Existing Security Measures in Cloud Paradigm for Big Data
- MapReduce Based N-List Structure for Fast Mining Frequent Itemsets Using a Novel approach
- Hadoop Distributed File System Framework Using Efficient De-Duplication Mechanism
- An Improved Ford Fulkerson Algorithm in Large Mesh Network to Determine Max Flow Using Hadoop
- Hadoop MapReduce for E-health Privacy and Security in Health Care System
- Cauchy Coding Approach for Improve Hadoop Distributed File System Performance
- Improve Heterogeneous Hadoop Clusters Performance for Big Data Using MapReduce
- MapReduce Schemes for Hadoop Word Count Using and Enhanced Estimation Models
- Protect Data Using Novel Scheme in HDFS (Hadoop Distributed File System)
- Large Scale Web Traffic Log Analyzer on Hadoop Distributed File System (HDFS) Using Cloudera Impala
- Analyze Network Motif in Iterative Hadoop MapReduce Clouds Sub-graph Enumeration
- Collaborative Filtering Based on Clustering for Big Data with Data Mining
- Hadoop MapReduce for Fingerprint Extraction and Matching
- Survey Distributed Prim’s Minimum Spanning Tree Construction Extensive Graphs Using Apache Spark
- Hadoop MapReduce Based Parallel Ant Colony Optimization for Edge Detection