MapReduce Projects
MapReduce Projects is the cerebral ecosystem to give the eternal lightning for you to set and visualize your goal to earn the culmination of success in your scientific pilgrimage. Our topmost skillful experts build our research organization as “Global Number 1 Organization” by their dedicative knowledge. Our primary aim is to create a students and researchers as a professional in the field of MapReduce. You can call us for any kind of guidance and support. We are greeting you with our blessed heart.
MapReduce Projects
MapReduce Projects give dynamic research zone for you to crop your name in the pinnacle of Everest. We are experts of expert in the MapReduce Projects development. Today, we organize numerous workshops and trainings in MapReduce for worldwide students and research Profs. We grant the real time MapReduce Projects training with our artistic and pioneering ideas for you to prepare highly advanced real time MapReduce projects by own.
Functionalities of MapReduce:
- Support replication [Distributed data store in to a number of machines]
- Support concurrent data access [Local caching and fetch contents from remote servers]
- Highly scalable for large data distributed and intensive applications [HDFS and Google file system]
- It does not consider or process bad records
Motivations of using MapReduce:
- Parallel across large clusters (hundreds/thousands of CPUs)
- Large scale data processing
- Reliable execution with ease of use
- Automatic distribution and parallelization
- Fault tolerance
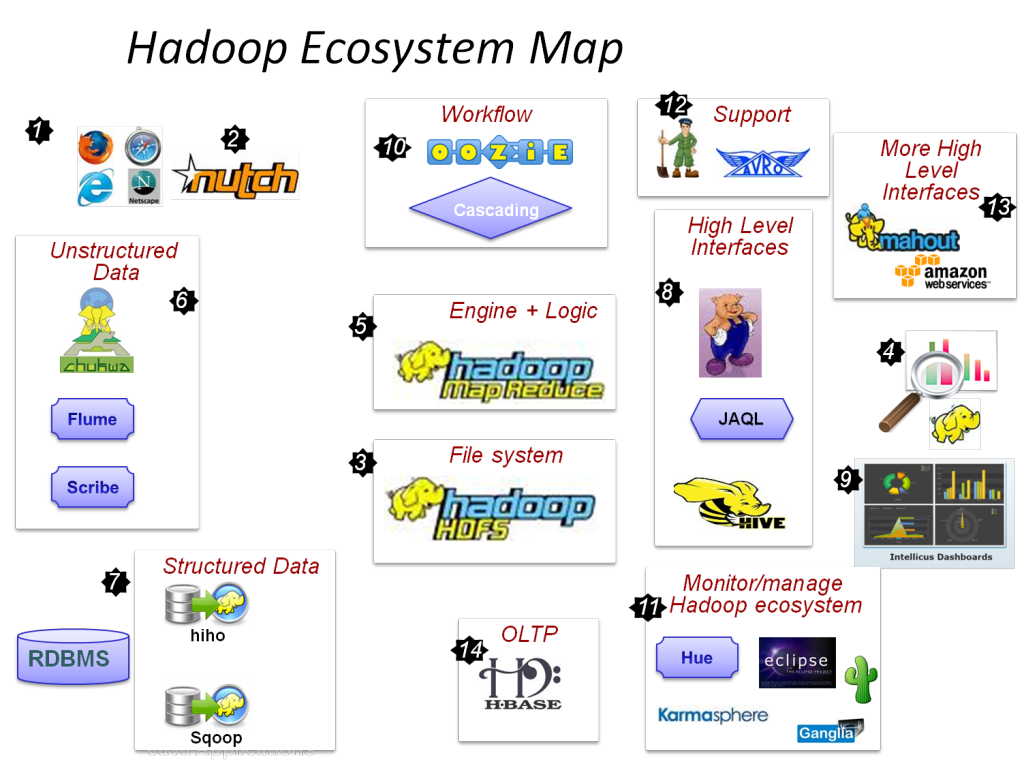
Major MapReduce Tools and its usage:
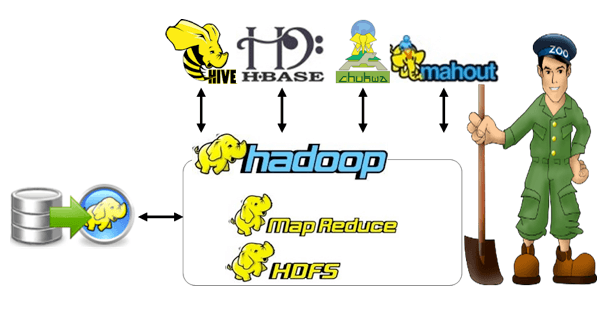
MapReduce: Software framework that consists of single master node and slave nodes. The master node is taken full responsible for scheduling user jobs.
HDFS: It expansion is Hadoop Distributed File System which act as storage system to store large data sets (Terabytes amount of data) and also it streams data in high bandwidth.
Avro: Avro is a tool that most suitable to refer and represent the complex data structures within a MapReduce framework
Apache Mahout: It is implemented on top of the Apache Hadoop using MapReduce paradigm. It is a library of scalable machine learning algorithms
Oozie: Java Web Application framework to integrate multiple jobs on a single unit. It is used to schedule jobs.
Apache Spark: It is open source big data analytics framework building on top of the HDFS.
Disco: Open source and lightweight framework that used in distributed computing
Gigaom: It is an open source software framework that compatible with C/C++ code
Spatial Hadoop: Extension of MapReduce framework that mainly created to access large scale spatial datasets
HIPI: Image processing library that designed to be used with the Apache Hadoop MapReduce
HBase: HBase is used for storing, and searching. It automatically shares the table across the multiple nodes.
SQOOP: It is a command line tool that controls the mapping between data storage and table.
GIS tools: Geographic Information Systems is used for geographical mapping which running on Hadoop.
MapReduce Integrated Tools and Usage:
- Amazon Elastic MapReduce to Dash Mobile: Dash Mobile API allows users to integrate and access the Das functionality with other applications.
- Misco: it is a distributed computing paradigm that mainly designed for mobile devices. It is compatible with Python and it is portable to run on any operating systems.
MapReduce Source Code Using Java:
/* Mapper Implementation
Public void map(Long writeable key, Text value, OutputCollector<Text, IntWriteable> output, Reporter reporter) throwsIOException {
String line =value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while(tokenizer.hasMoreToken());
word.set(tokenizer.nextToken());
output.collect(word, one);
}
/* Reduce Implementation
Public void reduce(Text key, Iterator <IntWriteable> values, OutputCollector<Text, IntWriteable> output, Reporter reporter) throwsIOException {
int sum =0;
while (values.hashNext()) {
sum+=values.next().get();
}
Output.collect(key, newIntWriteable(sum));
}
Current MapReduce Projects Titles:
- MapReduce and R Based Flexible Computational Paradigm for Permutation Test of Complex Traits Massive Genetic Analysis
- MapReduce Algorithm Based Weather Temperature Using Dig Data Prediction System
- Big Data Processing Based Hierarchical Hadoop System in Geo Distributed Frameworks
- Design Spark Based Intelligent K-Means for Big Data Clustering
- Hadoop Based Multi Kernel Parallel SVM (Support Vector Machine) Optimization
- Multi Source Heterogeneous Information Using FIM (Frequent Item-set Mining) Algorithm in Power Grid Intelligent Dispatching
- SVD Technique to Extract and Retrieve Compressed Text Data Unique Patterns on Hadoop Apache MAHOUT System
- User Preferences Set Similarity Based Big Data Applications Using Recommendation Framework
- IP Spoofing Typed DDoS Attack Using Detection and Analysis Techniques Based on Hadoop
- MapReduce for K-Nearest Neighbor Joins Parallel Computation
- Spark and Hadoop Using Efficient Data Access Approaches on HPC Cluster With the Heterogeneous Storage
- Earth Science Data Diagnosis and Visualization Over Spark and Hadoop
- Blocking Non-Matched Documents Probabilistic Parallelization for Big Data
- Design Approximation Algorithm Using Hadoop Architecture for Mapping Efficient DNA
- Analytics and Strom with Hive for Real Time Streaming Data Processing and Storage