Big Data Thesis Topics
Big Data Thesis Topics is the beginning point of all your desired achievements. At this scientific paradigm, we are designed our Big Data Thesis Topics for budding students and research academician to get the streamlined and comprehensive their knowledge. We are only working for students and research society with the main hope of fulfill their requirements from the first stage of research topics selection to last stage of viva voce. We deliver our Big Data Thesis Topics Service without any problem in interactive and well-coordinated manner. We assigned our universal celebrated experts for every students or researcher’s projects with the scope of focus mass of scholars individually with the complete domain and uptrend research knowledge. Do you need any support or guidance in Big Data Thesis Topics Selections? You can come towards without any delay.
Big Data Thesis Topics
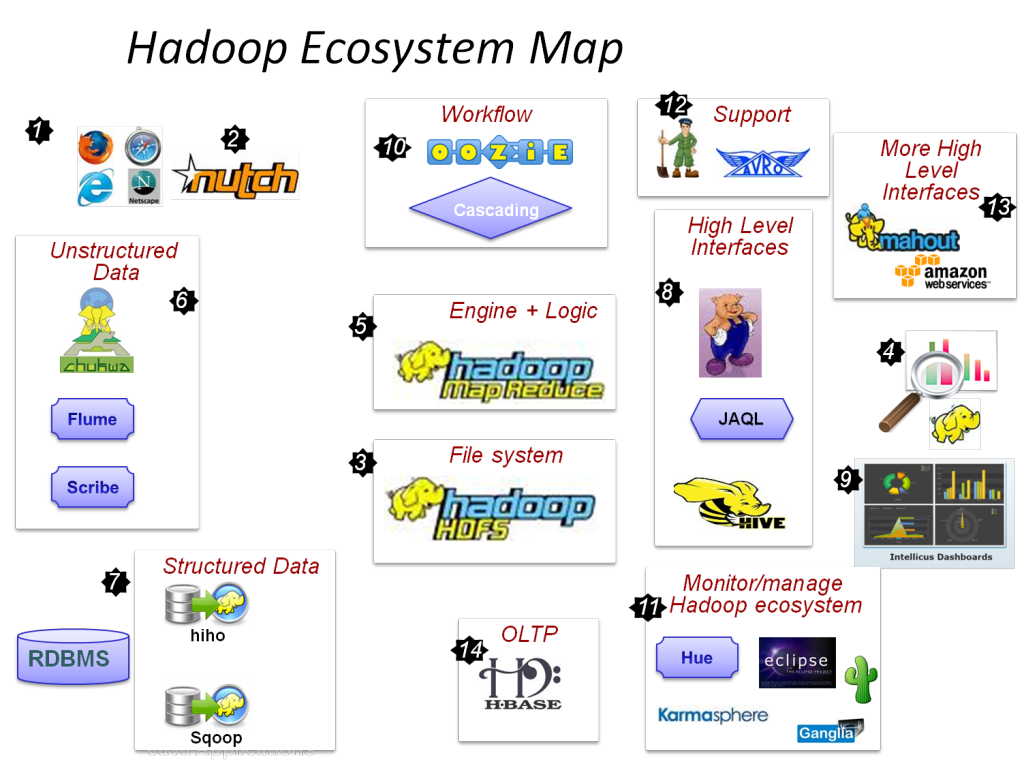
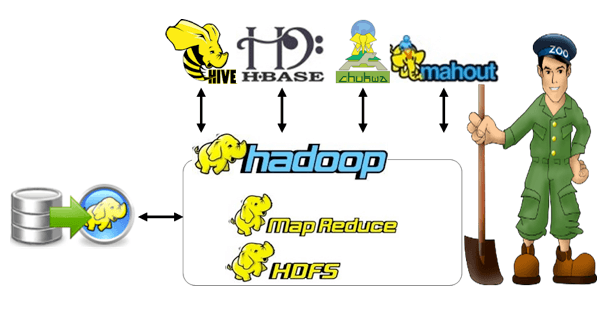
Big Data Thesis Topics service is introduced for the purpose of functioning students and research colleagues in Big Data paradigm. Today, managed Hadoop and Spark service uses Google Cloud Dataproc to process big datasets easily in the Apache Big Data ecosystem using powerful and open tools. We give the best training in Cloud Dataproc integration of computer, storage and monitoring service which processed through cloud processing platform.
Why Choose Big Data as a Thesis Topic?
- To reduce the computation cost
- Faster and better Decision Making
- Perform Risk Analysis
- New Product and Services
Major Applications of using Big Data as a Thesis Topics:
- Data Virtualization (Data abstraction and DF component)
- IoT Analytics (Access Data from anywhere)
- Data Federation (Data integrate from anywhere)
- Point in Time Analysis (Gather Big Data over a Small Duration)
- Multi-Voxel Pattern Analysis (Human Brain Decoding and Deep Learning)
One of our Best Thesis Structure in Big Data:
Table of Contents
-Introduction to the Study
- Background
- Purpose
- Research Questions
- Empirical Setting
- Limitations
- Disposition of the research
-Theoretical Framework
- Innovation Management
- Area you focus
- Implementation of area you focus
-Methodology
- Research Strategy
- Research Design
- Research Method
- Primary Data Collection
- Secondary Data Collection
- Sampling
- Data Analysis
- Research Quality
-Empirical Findings
-Analysis
- Key success factors
- Performance analysis with existing solutions
-Conclusion
- Recommendations
- Future Research
-References
-Appendixes
Latest Big Data Thesis Topics:
- Machine Learning Algorithms and Wearable Technologies for Fall Recognition
- Korean Morphological Analyzer Construction Using a Grapheme Level Strategy without Linguistic Knowledge
- Divergence and Convergence on Internet of Things (IoT) Based Manufacturing in Industrial and Academics Interests
- Symmetric Bisecting K-Means Centers Repositioning for Big Data Clustering to Enhanced Distance Calculation Reduction
- Reliable Data Movements Using Bandwidth Provision Strategies in Dedicated Networks
- Hierarchical Change Detection System Based on Scalable Nearest Neighbor for Monitoring Crop
- Big Bata Analytics Using Artificial Neural Networks for Player’s Patterns Recognition in Cloud Gaming
- Online Anomaly Detection in Cloud Collaborative Environment for Data Streams Using Non-Parametric Technique
- Shape Matching for Automated Bow Echo Detection Using Skeleton Context
- Cloud Computing Leveraging for Grid Responsive Buildings to Non-Intrusive Monitor and Powerful Framework conversion
- Enhance Maximizing Spread Efficiency for Large Sparse Networks in the Flow Authority Model
- Hash Neighborhood Candidate Generation and Probabilistic Signature Hash Method on Big Data
- Automated Extremist Twitter Accounts Classification Using Network Based and Content Based Features
- Linked Data Paradigm for Connecting API Access and Building Cloud Based Smart Applications with Data Discovery Approaches
- Adapting for Decomposition of Efficient Parallel PARAFAC Tensor to Data Sparsity in Hadoop