Hadoop Projects for Students
Hadoop Projects for Students is the awe-inspiring pathway to outreaching your daydream of success in rapidly. We offer overwhelming Hadoop service for undergraduate students (BE, BTech), post-graduate students (ME, MTech, MCA and MPhil) and research academicians (MS/PhD) to develop their knowledge in Hadoop implementation. We give our excellence of best assistance and guidance for scholars to do miraculous achievements in their future professions. Scholars we offer our best for the most reason of make you as a Hadoop expert in this scientific paradigm. You journey was tough, but you have an excellent idea. You never lose your interest and effort, which eventually brought you to success. If you really aspire to do something grand with our guidance, call us our universal class scholar’s care service. We are happy to serve you with our cheerful hearty.
Hadoop Projects for Students
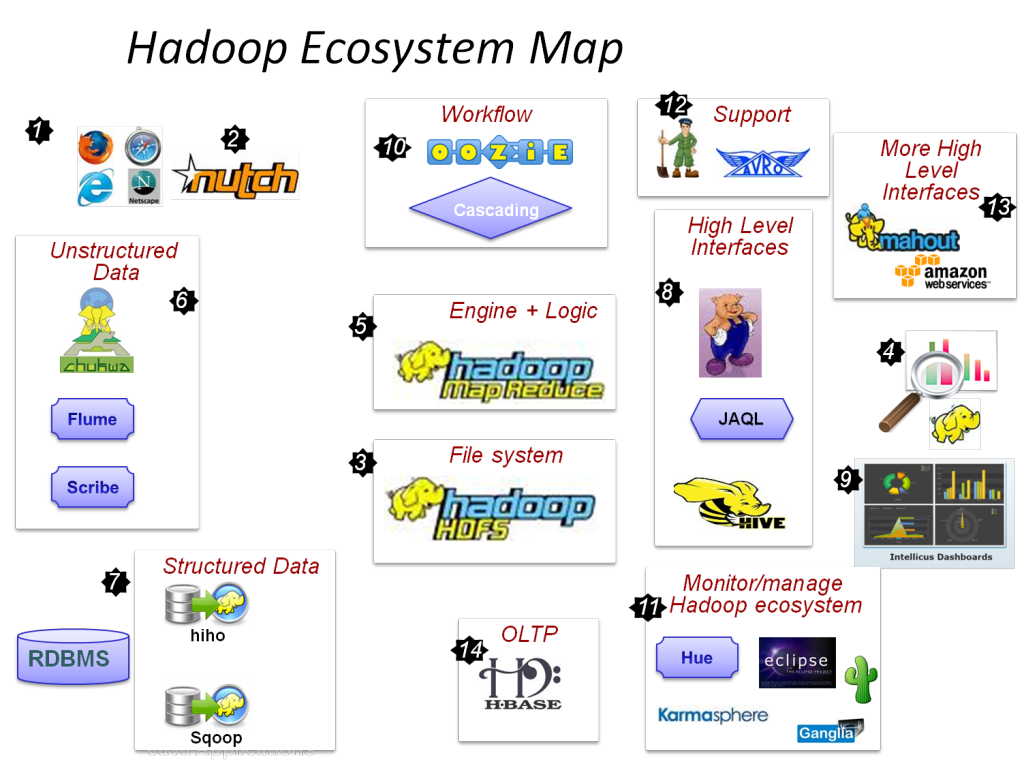
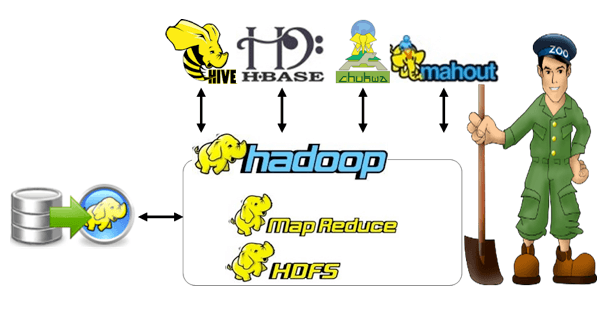
Hadoop Projects for Students grant ultramodern technological zone for scholars with the good aspiration of generate knowledge revolution. Day by day we refresh our knowledge by uptrend technologies including latest versions of tools and software, mechanisms, approaches etc. On Account of this, we can provide our updated knowledge for students and research colleagues to improve their knowledge in Hadoop and software packages including Apache Oozie, Apache ZooKeeper, Apache Hive, Apache Strom, Apache HBase etc.
Our Hadoop Training Program RoadMap for Students:
- What is Big Data and its Current Issues?
- Why we go for Hadoop?
- Hadoop Overview and Ecosystem
- Understanding of Hadoop Clusters
- HDFS Schema Design
- MapReduce Anatomy
- MapReduce Programs Development
- Advanced MapReduce Algorithms
- Advanced Tips and Techniques
- Management and Monitoring of Hadoop
- Using Pig and Hive for programming
- Deploying Hadoop on Cloud
Hadoop Features:
- Hadoop prevent the attack of cross site scripting over JMXJSONServlet
- It support for Quota for storage types
- Use Cygwin for launching Hadoop processes on windows with reinstate support
- While creation of JCEKS avoid uppercase key names
- Inodes leakage occurs permanently due to the deletion failure
- Create Hadoop trunk with Java 7+ only
- 32 bit windows machine has failed in Hadoop
- It support Blob as a file system and Windows Azure Storage in Hadoop
- Use shared thread pool to S3A OutputStream for solve OutOfMemory error
Prerequisites of Hadoop:
-Hadoop Version (any version)
- Apache Hadoop 2.8.0 (Latest version)
- Apache Hadoop 4.0, 2.6.0, 2.7.2, 2.7.3(Old versions)
-Hadoop Operating System
- Solaris
- Microsoft Windows 7, 8 or 10 [64 bit OS]
- Apple MacOSX
- Linux/GNU/Ubuntu 04.3 LTS, 12.04, 14.04, 10.04 etc.
- CentOS
- RedHat
-RAM
- Minimum 2GB
- Maximum 4GB
-Processor
- Pentium above
-Required Software
- Java 1.5+ (Oracle JDK 1.6/6)/ Sun Java 6 JDK
- OpenSSH configuration
-Core Languages for MapReduce Functions
- Perl, C, Python, Ruby etc. [Any language]
-Supported Browsers
- Firefox [latest stable release]
- Internet Explorer 9
- Google Chrome [latest stable release]
-Database Software
- MySQL/Apache HDFS
-VMWare Player/VMWare Server/VMWare Workstation
Few list of Titles of Hadoop Projects for Students:
- Directed Model Crash Traces and Checking Using Bug Reproduction Scheme
- Fault Explanation and Detection on Sensor Streams Over Big Data Analytics
- Azure Cortina and Internet of Things Intelligence suite in Real Time Business
- Enhance Big Genomic Data Analysis Performance Using a Novel Cost Effective Approach in Clouds
- Root Cause Analysis Using Data Driven Solution in Cloud Computing Environments
- Big Data Sales Forecasting Using Parallel Aspect Oriented Sentiment Analysis
- Large Scale Railway Networks Using Dynamic Delay Prediction for Shallow and Deep Extreme Learning Machines over Threshold-out
- Enrich Performance on Heterogeneous Hadoop YARN Using Container Deployment Based on Efficient vCore
- Enhance Heterogeneous MapReduce Clusters Performance with Adaptive Task Tuning
- Item Based Collaborative Filtering Recommendation Algorithm Using an Optimized MapReduce with Empirical Analysis
- Spatial Coding Based Mechanism in Hadoop for Partitioning Big Spatial Data
- Optimization of Big Data Analysis Performance in Distributed Platform Using an Innovative Pattern Classifier Mechanism
- Principle Component Analysis Based on Hadoop in Embedded Heterogeneous Platform
- Distributed Computing Infrastructure for Distribution Feeders Optimal Control with Smart Loads
- Bayes Classifier Based Algorithm on Big Data Platform for Massive Stream Dat