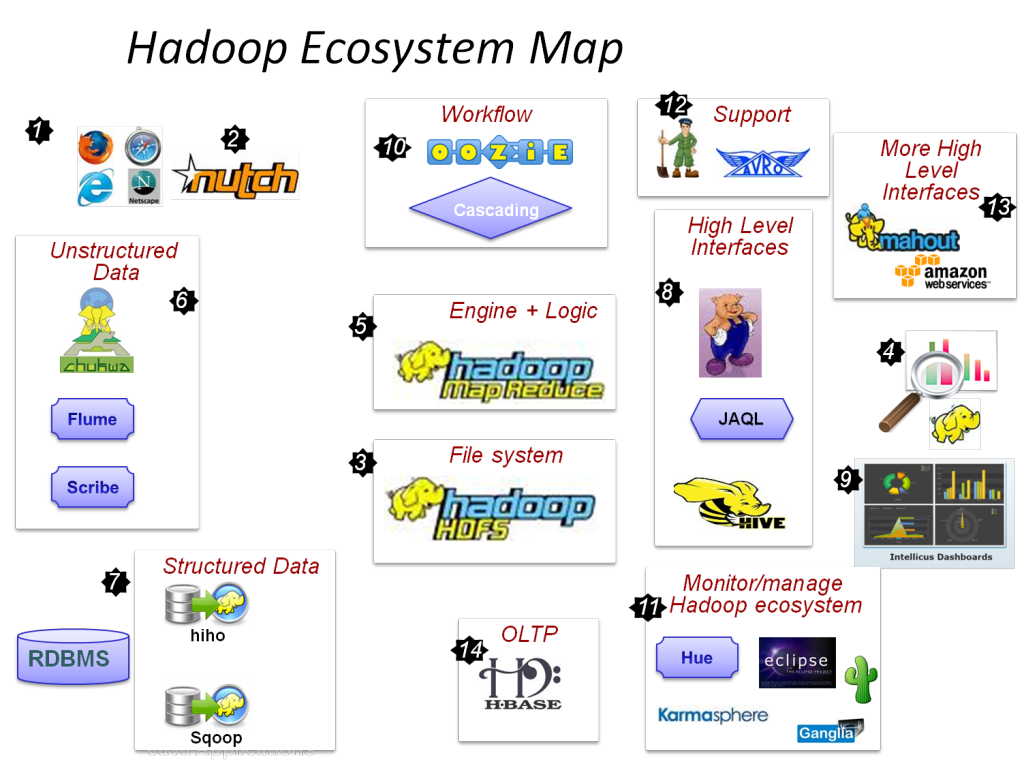
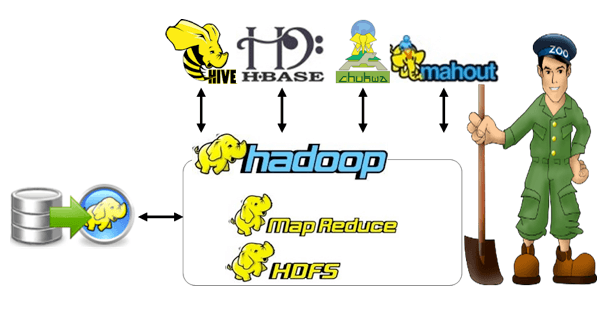
Hadoop Research Projects
Hadoop Research Projects give the meritorious biosphere for you to get supreme accomplishment in your world taking academic pilgrimage. Our Hadoop Research Projects Services establish to work for national and international level research scholars and students from various departments include computer science, information technology, electrical and electronic engineering, electrical and communication engineering. Our “world Top No 1” research institution is backed by our team of miraculous skillful experts who have immense of experience in Hadoop development. Do you have high enthusiastic to utilize our fruitful experience? You can come closer by our 24 hours live-in care.
Hadoop Research Projects
Hadoop Research Projects is the energetic and positive research surfaces for mimic your forthcoming success. We guide our scholars by our creative ideas and genius thoughts to get high grade in their academic curriculum. To develop your profile as the best, we grant our marvelous service for you such as statistical analysis support, proofreading support by our experts, research paper rewriting, research paper & research proposal preparation, peer review support, plagiarism free thesis preparation support, free abstract preparation support etc.
Data Modelling in Hadoop Framework:
Considerations include:
- Multitenancy
- Data Storage Formats
- Metadata management
- Schema Design
Data Storage Options:
- Compression
- File Format
- Data Storage System
Standard File Formats:
- Text Data (XML or CSV file)
- Binary file types (such as images)
- Structured text data (JSON and XML)
- Built-in Input format
- Binary data
Hadoop File Types (Avro, and Columnar formats [Parquet and RCFile]):
- Agnostic Compression
- Splittable Compression
- File based data structures
-Record-compressed
-Uncompressed
-Record-compressed
-Block-compressed
- Serialization formats
Important Aspects of File Formats in Failure Handling:
- Columnar formats: It does not work with failure events, this can lead to the problem to incomplete rows
- Avro: It work well in the best failure handling even the event holds bad record, but the problem is it will affect some portion of a file
- Sequence files: These files can easily include but failed to read in row and also not recoverable at any cases.
Data Compression plays a vital role in Hadoop Data Processing. The important consideration is storing data on Hadoop, but it’s not just reduce the size of the data, it’s also improves the data processing performance in Hadoop.
Data Compression Tools/Toolkits:
- Snappy [High speed compression codec with reasonable compression]
- LZO [Good choice for plain-text files]
- GZIP [Good performance with high speed compression]
- Bzip2 [excellent Compression performance]
Some General Examples of Hadoop:
- BBP: Short for Bailey-Borwein-Plouffe that used in MapReduce programs to compute the exact digits of PI
- GREP: It is a MapReduce program that used to counts the matches to a regex in the input
- JOIN: It is a job that effects a join over equally and sorted partitioned data sets
- DBCOUNT: It is used to counts the pageview counts from a database
- DISTBBP: It is a MapReduce program that uses a BBP-type formula to compute the exact bits of Pi
- Aggregate WordCount: For a given files, counts the words using aggregate based MapReduce program
- AggregateWordhist: It computes the histogram of the words using aggregate based MapReduce program
- MULTIFILEWC: It is a job that computes number of occurrences of a word in a given input files
Some Recent Hadoop Research Projects Titles:
- Enhance Heterogeneous Yet Another Resource Negotiator (YARN) Performance Using Container Deployment Algorithm Based on Efficient VCore
- Massive Remotely Sensed Data In-Memory Parallel Processing on Hadoop Yarn Paradigm Using Apache Spark
- Evaluate Cloud Based Log File Analysis Performance with Apache Spark and Apache Hadoop
- Hadoop Based Distributed Nearest Neighbor Classification Using Framework
- Enable Fast Failure Recovery Towards Failure Aware Scheduling in Shared Hadoop Clusters
- Tessera Framework for Social Media Data Analytics in Hadoop Cluster Platform
- Metadata Management Based on Prefetching in Advanced Multitenant Hadoop
- Multidimensional Layered Hidden Markov Scheme for Scalable Cloud Resource in Big Data Streaming Applications
- Human Activity Monitoring Using Activity-aa-Service Cyber Physical system Based on Cloud in Mobility
- Evaluate Spark and MapReduce Applications Performance Using Fluid Petri Nets
- Compare Distributed Computing Paradigm Using Dynamic Algorithm Modeling Application
- Compute and Data Intensive Pipeline Applications Using Containerized Analytics Paradigm
- Coupling Cluster Computing Integrate with Distributed Embedded Computing Using Energy Efficient and Scalable Resource Manager
- High Throughput Vehicle Engineering Data Analysis and Processing Using Big Data Scalability
- Recognize Lobesia Botrana Using Distributed K-Means Segmentation Algorithm