What are some latest research big data analysis research topics? The data generation process is constant with the ever-changing and increasing rate. Imaging technologies, mobile phones, and social media are used to determine the medical diagnosis process with all the analytical data entities. The fundamental ideas are based on the structure design of data and the meaningful pattern recognition process with all the essential objects and functions.

Big data – Data analytics life cycle
- Discovery
- The discovery section is used to acquire some knowledge about the project domain and that consist of the significant history of the field
- In terms of data, time, people and technology are the resources for the team which is used to access
- Project problem is framed through the analytics challenge and that is addressed using the consequential sections with initial hypothesis formulations
- Data preparation
- It is the analytics sandbox where the performance analytics and data as per the duration of the project
- Extract, load, and transform (ELT) and extract, transform and load (ETL) is used to collect the data in the sandbox
- The data transformation process takes place using ETLT is used to analyze the data
- In addition, it is acquainted with data as per the steps used for the process
- Model planning
- Model planning is used to determine the techniques, workflow with intention, and methods used for the model creation
- The relationship between normal variables and consequential variables is explored in this section
- Model building
- This section is used to enhance the data sets to produce, train and test the data and implement the models which are related to the model planning phase
- In this phase, the system has to determine the sufficient process of existing tools with the running models and the necessity of a robust environment
- Communicate results
- It is used to associate the stakeholders with the determination of project results as per the developed criteria
- The team has to recognize the quality of business values, enhancements in narration and summarizations, and significant results and convey the results to the stakeholders
- Operationalize
- This phase highlights the final report delivery with the technical document, code, briefings, etc.
- The functions of pilot project implementation are used to model the production environment
The above-mentioned are explanations of the life cycle of data analysis. Our research experts have highlighted all the significant phases in the process of data analysis for your reference. We assist research scholars in designing big data analysis research topics.The following is about the benefits of analytical methods using clustering.
Advanced analytical method: Clustering
- Expectation maximization clustering using GMM
- It is used as the alternative algorithm for the K-Means algorithm and in GMM, it is anticipated with the data points and that is denoted as Gaussian distribution
- DBSCAN algorithm
- The density-based spatial clustering of applications with noise is abbreviated as DBSCAN
- It has some remarkable advantages and the density-based model is similar to the mean shift
- The process of this algorithm is to separate the areas of high density from the areas of low density and the clusters are recognized as the arbitrary shapes
- Mean shift algorithm
- It is used to attempt the dense area identification and the smooth density of data points
- Centroid-based models are used to update the candidates for centroid with the center point of the region
- K-Means
- It is the collection of objects with all the numbers based on measurable attributes
- It is the analytical technique that selects the value of K and recognizes the k clusters with the proximity of the objects
- Use cases
- Classification is led through the process of clustering. Notably, the clustering is recognized and the labels are applied for the cluster and which classifies the characteristics
- The applications such as customer segmentation, medical and image processing for K-Means are highlighted in the following
- Image processing
- Video is considered one of the examples of image processing and the growth of volumes in unstructured data is collected
- In addition, all the frames of video and k-means analysis are used to recognize the objects related to the video
- It is used to determine the pixels which are similar to one another
- The attributes of all the pixels consist the features such as
- x and y coordination of the frame
- Color
- Location
- Brightness
- Medicine
- The clusters in this algorithm are used to identify the characteristics of patients such as
- Level of cholesterol
- Height
- Age
- Weight
- Systolic and diastolic blood pressure
- Other characters
- In addition, the clusters are used to aim the individuals to measure the clinical trial participation
- The clusters in this algorithm are used to identify the characteristics of patients such as
Advanced Big Data Analytics Projects – Technology and tools
MapReduce is used to provide the functions of parallel tasks, and interrupt of the massive task as the small tasks, and it is deployed to consolidate the results of individual tasks towards the final output. We help in programming phase of implementing projects based in big data analysis research topics. The name itself denotes that it has two significant parts such as
- Map
- Intermediate outputs are provided
- Operation is deployed to the piece of data
- Reduce
- Associates the intermediate outputs from the map steps
- Offers final results
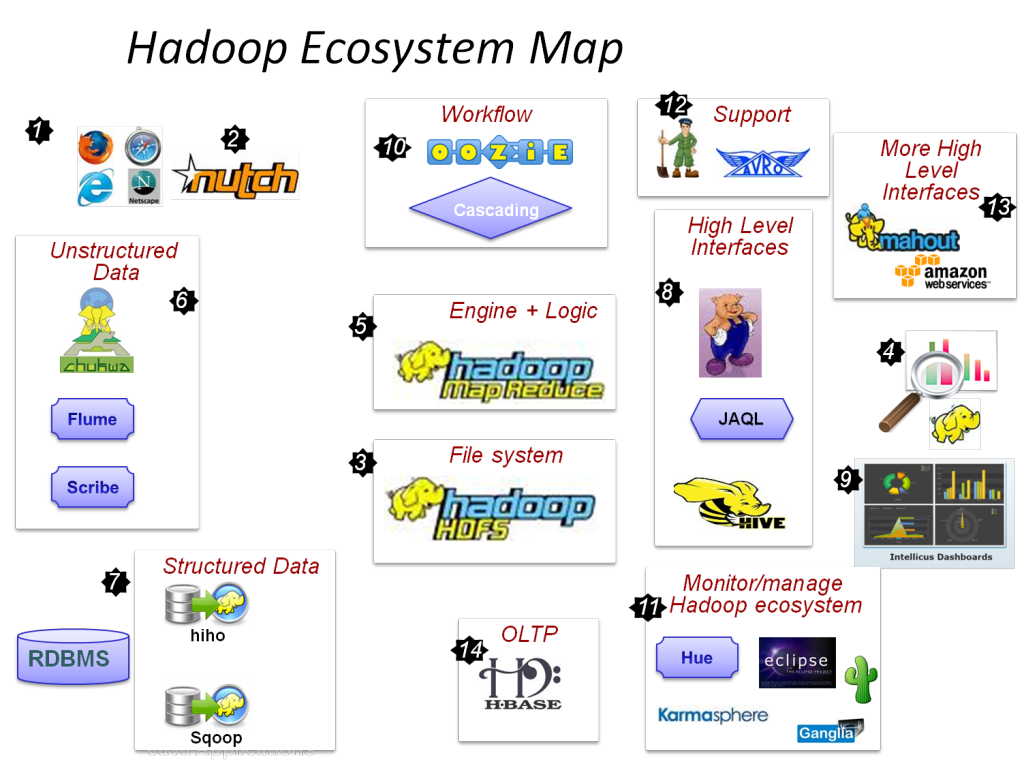
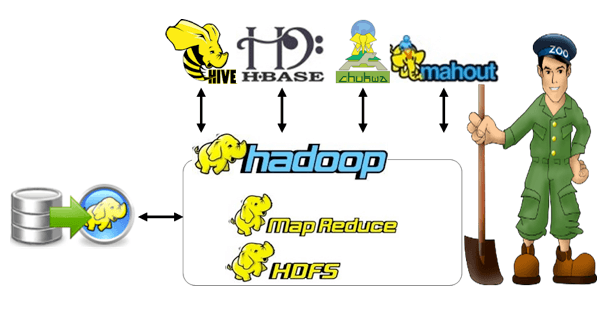
Examine the Hadoop related apache projects
- HBase
- Provision of real-time writing and reads
- Mahout
- Offers analytical tools
- Hive
- Provide the SOL-based access
- Pig
- Deliver the high-level data flow with programming languages
Big data project titles
- User-centric similarity search
- User preferences have a notable phase in the process of market analysis
- The literature on the database may have some extensive work with the embryonic queries
- The top-k query is deployed to position the products based on the expressed customer preferences
- It is beneficial for the functions of product positioning based on the feedback given by the customers and it maps the products as per the user-centric space
- Data partitioning in the frequent item set mining on Hadoop clusters
- Massive datasets, strategies for data partitioning with the solutions at present based on smart mining and communication which is induced through the redundant transactions for the computing nodes are offered
- The FiDoop-DP is used to address the issues with the enhancement of the data partitioning approach through the MapReduce programming model
- The main intention of FiDoop-DP is to develop the performance which is parallel to a frequent item set mining on Hadoop clusters
To mention a whole thought of the big data analysis, we have created this page for your reference. We hope that you got a general idea about the big data analysis research topics. Our research experts assist with all your research needs. So, join hands with us to reach better heights in research.