What is big data analytics? How to choose an interesting big data analytics PhD Topics for my research work? Big data analytics is a novel and vast research platform for researchers because the projects based on big data are the real-time implementation process. The fundamental analysis of big data has spreadsheets, etc. with manual implementations.
What is Hadoop?
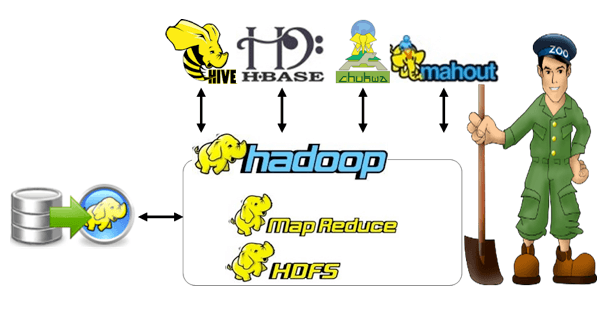
Apache Hadoop is the open source framework with large-scale distributed processing and it is established as novel enterprise data sets. In place of being dependent on expensive and various systems to process and store data, Hadoop is using the distributed and parallel processing of huge amounts of data. The big data analytics PhD topics should be innovative and it is beneficial to develop the research.
Why big data Hadoop?
The process of analyzing and categorizing big data is used to assist the project predictions. Hadoop permits enterprises to collect data in various forms and add more servers to the Hadoop clusters.
- The data storage in Hadoop is not expensive as the data storage methods which are used before
- All the servers are used to add power to the clusters through processing and storage

Hadoop and big data
- The scalability, cost-effectiveness, and systematic structural design of Hadoop are essential for the process of implementation and big data regulation
- Hadoop is essential to handle the big data workloads and optimize the structure of data management
Different modes of operation – Hadoop
- Fully distributed mode
- Data is distributed for various nodes
- Hadoop production mode is deployed to illuminate the modes in physical terminology
- The multi-node cluster is considered a significant phase and it is deployed to run the name node and resource manager in the master Daemon
- Slave Daemon is functioning as the node manager and data node
- Standalone mode
- The standalone mode is mainly functioning through Hadoop and it is also called the local mode. Hadoop is notably used in the functions of debugging, learning, testing, etc.
- The standalone mode is the installation of Hadoop in a single system. In addition, node manager and resource manager are utilized through Hadoop2
- There is no functioning based on Daemons such as data node, name node, job tracker, a task tracker, and secondary name node
- Task and job tracker are processing in Hadoop1
- Pseudo distributed mode
- It is used as the single node and through the cluster simulation. It is related to the process of cluster functioning independently
- The daemons are functioning separately in the separate java virtual machine and the daemons such as node manager, data node, resource manager, name node, secondary name node, etc. In addition, various java processes are functioning in this mode and it is denoted as a pseudo-distributed phase
Features of Hadoop which make it popular
The notable features of Hadoop are more reliable to use, the powerful big data tool, industry favorite. Why Hadoop is chosen as a programming language to solve big data analytics PhD topics.
- Highly scalable cluster
- The fundamental relational database management system is not beneficial for scaled approaches to a large amount of data
- The nodes and machines are used to increase and decrease the requirements in enterprises
- Division of huge amounts of data into the various inexpensive machines based on the cluster as the parallel process and Hadoop is considered the highly scalable model
- Hadoop uses data locality
- The moving data in HDFS costs expensive with the assistance of the data locality concept and the minimization of bandwidth utilization in the system
- Computation logic is stimulated to the adjacent data instead of the computation logic and it takes place in the data locality concept
- The fast process of Hadoop is the foremost process of the concept of data locality
How to create GitHub data repository?
The data scientist and all the programmers can use GitHub and the Git repository hosting service for their work or any other project-related work.
How does big data work?
- Integration
- The process of data blending through various sources and the transformation of data into a relatable format for analysis tools for further functions
- Management
- The traditional cloud environment is the provision of various concurrent processing functions and scalability for the essential big data processing
- The transformation of unstructured data is to imitate the rows and tables in relational type which is required the huge effort
- Big data is ingested with the repository functions and it has simple functions in storage and access
- Big Data Analysis
- The analyzing process of humongous data sets with artificial intelligence and machine learning tools is uncovered
Where does big data come from?
The following are important parameters to choose an interesting big data analytics PhD Topics.
- Posts in social media
- Histories based on transactions
- Interactions among the websites
- Internet cookies
- Smartphones and wearable devices
- Transaction forms in the online purchase
- IoT sensors
The numerous ways are required to collect big data, abovementioned are some of the notable ways used to collect big data. In the following, we have highlighted the demo big data Hadoop project for your reference.
Demo big data Hadoop project
Visualizing website clickstream data with Hadoop
- The clickstream data are collected in the semi-structured web log files and that includes various data components such as
- Destination URL
- Referral page data
- Device information
- Visitor identification number
- IP address of the visitor
- Data and timestamp
- Web browser information
- The recording process of various parts in the computer screen when the user is browsing any application or website is called the clickstream
- The functions of the user while clicking the different sections in web pages are reordered on the web server
Problem Statement
- Various complex tasks are applicable in process of streaming and storing the data about customers through the traditional databases and it requires the maximum amount of time to analyze and visualize the process
- A massive amount of eCommerce strategy is essential to analyze and track the clickstream data
- Various tools are used to solve the problems in the Hadoop environment. In addition, the format based on JSON data is loaded and the data is analyzed in Hive
What will you learn from this big data Hadoop project?
- Analysis of log files in Hive
- Populate and filter the data by producing query
- A table is created to copy the data
- In Hive, the external table function to manage the queries
- The schema is generated for the files in the table
- Loading and analyzing JSON format to Hive
The big data analytics PhD topics can cause a major impact on your career as a research scholar and professional. So we are the right platform to select the appropriate topic with experienced and hardworking research experts in big data analytics.