What are some latest interesting big data capstone project ideas? Big data capstone project is the provision of techniques and theories which are enlarged from various courses in medium-scale data science projects. Mainly, it is considered the function of real-time data sets, and it is used to enhance the skills and knowledge based on data science.
What does Hadoop mean?
Hadoop is the framework of open source software where it is used to store the data and the functions of applications based on the hardware commodity. Hadoop is used to provide a large volume of storage for various kinds of data
What are the ETL project tools in Hadoop?
- The ETL tools are used to connect the data sources such as
- Apache ZooKeeper
- Apache Pig
- Apache Phoenix
- Apache Hive
- Apache HBase
- Apache Oozie
- Apache Sqoop
- Apache Flume
- The data architecture is essential for various causes in the process and it is related to the type, rate, and amount of new generation data
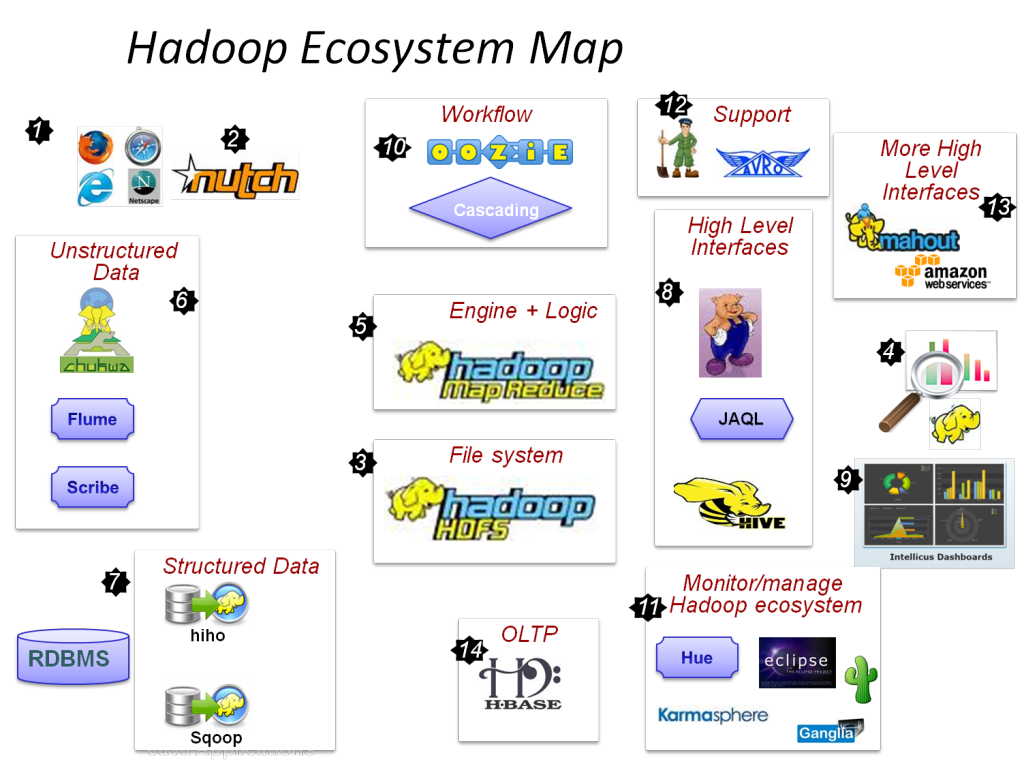
Project in Hadoop Ecosystem
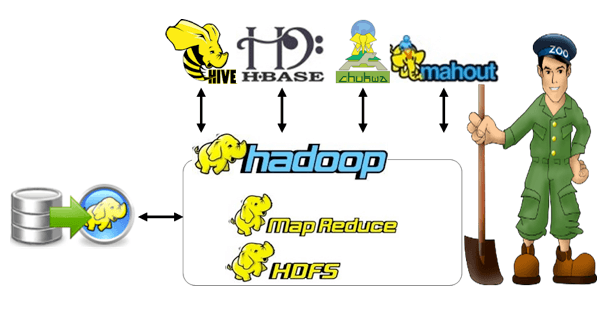
MapReduce and HDFS are the two notable components in the Hadoop environment and they have a significant place in the Hadoop framework. In the Hadoop environment, there are various apache projects are available in the Hadoop framework. Our Hadoop experts will guide research scholars to craft novel big data capstone project ideas. The following is about the notable apache project or framework.
- Management and monitoring
- Distributed storage
- HDFS
- Distributed processing
- MapReduce
- Data integration
- ODBC
- REST
- Sqoop
- NoSQL database
- HBase
- Query
- Hive
- Machine learning
- Mahout
- Scripting
- Pig
- Workflow and scheduling
- Oozie
- Coordination
- ZooKeeper
- Distributed storage
Apache Pig
Pig Latin is also called Apache Pig and it is the significant software framework that provides the functional time environment with the implementation of MapReduce tasks based on the Hadoop cluster through the high-level scripting language. The specific functionalities of this Apache Pig are highlighted in the following
- In general, Pig provides several functions, creating operators and making the common performance
- Hadoop is the provision of shell which is called as executing pig commands as the Grunt shells
- Pig lain queries are observed with several tasks in MapReduce and the implementation of Hadoop clusters
- Pig generalizes the programming languages which are at a high level in the Hadoop cluster
Apache Hive
The framework of the Apache Hive data warehouse is functional for the process of residing, querying, and managing the massive datasets in the distributed file system which is related to the Hadoop distributed file system (HDFS). The features such as,
- The Hive QL queries are implemented through MapReduce. In addition, the HiveQL query is distributed and that triggers the tasks in Reduce and Map for the functions which is the query
- Hive permits functions such as
- Custom user-defined tasks
- Custom mappers
- Custom reducers
- Notably, it is functional for several sophisticated operations
- The unique database is denoted as the Hive Metastore
- SQL language is used to write the Hive queries and that is called HiveQL
- Hive regulates the system catalog in internal data such as
- Partitioning information
- Hive tables
Apache Mahout
Apache mahout is the data mining and scalable apache machine learning library and the specifications in the projects are listed below
- Mahout library has two types of algorithms as
- Functional is distributed fashion
- Functional in local mode
- Mahout executes the data mining and machine learning algorithms with the usage of MapReduce
- Mahout includes four various categories of algorithms such as
- Classification
- Collaborative filtering
- Dimensionality reduction
- Clustering

Apache HBase
Apache HBase is considered as the column-oriented, distributed, scalable, big data store and versioned at the top of HDFS. In the following, major functions of the Apache HBase are listed,
- HBase is the provision of consistency in reading and writing and it provides the uses of Java APIs for clients
- The function in the commodity cluster hardware and balance of the linearity
- It assists several columns and rows
- In distributed fashion, it is deployed on top of Hadoop and HDFS
- The HBase is related to the concept based on Google Big table
Apache Sqoop
Apache Sqoop is a significant tool created with full efficiency for transferring the data among Hadoop and relational databases (RDBMS). The highlights based on Apache Sqoop are noted below,
- MapReduce is used in Sqoop for the process of export and import of the data with effective utilization of parallelism and the fault tolerance functions in Hadoop
- Sqoop is functional for the process such as data import and data export from HDFS, data warehouse, relational databases, and Hive
- Data importing is incrementally permitted through Sqoop towards the HDFS
- It is efficient to transfer the entire data among relational databases and HDFS
Apache Oozie
Apache Oozie is the workflow of scheduling and managing the tasks that are implemented in Hadoop as the coordination manager. In addition, the highlights of the projects are listed below
- It is organized in the directed acyclic graph (DAG) fashion
- The tasks that are scheduled and implemented in Oozie are related to the obtainability of data and scheduled frequency
- It assists with various tasks such as Sqoop, Pig, MapReduce, Hive, etc.
- Oozie is integrated with Hadoop and it is the custom default in the Hadoop environment
- Oozie has the both MapReduce and non-MapReduce functions
Apache ZoopKeeper
Apache ZoopKeeper is based on distributed applications and is an open-source coordination service. The specific features of the project are highlighted in the following,
- It provides the required tools to write the distributed applications and that is used for the effective synchronization
- It is used to maintain the information configuration and provide the distributed fashion coordination
- It is created as the centralized service
Apache Ambari
It is used for managing, monitoring, and provisioning the Hadoop clusters and it is the open source software framework.
- Ambari provides the required centralized management clusters such as
- Starting and finishing point of the cluster
- Configuration and reconfiguration services
- It is used to install the Hadoop services through various cluster nodes and manage the cluster which is configuring the Hadoop services
Hadoop Sample Projects
- Mathematical models on the Hadoop runtimes on big data
- The mathematical models anticipated as the hired process from the system and the data process is parallel
- Formula of simple runtime is implemented and it uses the numerical methods to predict the runtimes and for data accumulation
- Contribution
- Machine cluster is increased
- Reduction of processing time
- Increase in runtime
- Big data representation for grade analysis through the Hadoop framework
- The software and hardware solutions are applicable in the technological landscape and that is used to store, capture and analyze the big data
- Hadoop is used to compute a large amount of data and it is the software framework
- Hadoop is accompanied by the technological solutions
- Contribution
- It executes the cloud structural design based on AWA with the provision of Amazon
- In the educational framework, big data is the exemplification of grade analytics
To this end, we have provides an article that is related to big data research. Our research experts in big data have years of experience in this research field, through the years of experience we have completed several research projects in big data analytics. So, the research scholars can reach us for interesting big data capstone project ideas. We provide excellent service for the research. In addition, our research experts are here to fulfill all your research requests with the best innovations in the research field.