How to implement big data machine learning projects? Big data denotes tremendously huge sets which include structured and unstructured data that cannot be regulated through the utilization of the traditional methods. Big data analytics has the ability that creates a sense of the data through the process of detecting trends and patterns.
Machine learning can increase the speed of this process with the assistance of decision-making algorithms. It can classify the incoming data, recognize patterns and translate the data into insights that are ready to lend a hand to business operations. Machine learning algorithms are advantageous in the process of collecting, analyzing, and integrating data for large organizations. They can be implemented in all elements of big data operation, including data labeling and segmentation, data analytics, and scenario simulation.
What is big data?
The technologies and initiatives based on big data are used to analyze the data to attain insights that can help the creative process of strategic decisions. Big data denotes a massive volume of data sets that might be structured or unstructured. The process of big data analytics is to analyze the huge data sets which are employed to feature the patterns and insights of big data machine learning projects.
Big data architecture style
The architecture of big data is designed to manage the processing, analysis, and ingestion of data which is vast in size and it is even more complex than traditional database systems. Big data solutions are typically involved in various types of workloads such as,
- Predictive analysis and machine learning
- Interactive exploration in big data
- Big data real-time processing
- Batch processing of big data sources
Collection of big data
Big data is collected from a variety of sources, thus it is named big data and it owns it. Reach our experts if you struggling to develop big data machine learning projects. Some of the significant sources are highlighted below
- Social media
- Third-party cloud storage
- Online web pages
- Internet of things

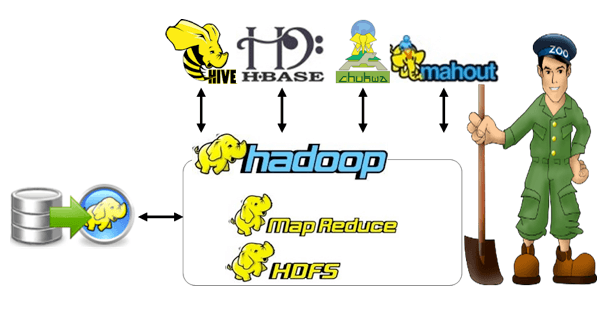
Components
There are several components in big data architecture such as
- Data sources
- The functions of big DAT start with various data sources and the significant data sources such as
- Real-time data sources
- IoT devices
- Application data stores
- Relational databases
- Creation of static files through applications
- Web server log files
- Data storage
- The distributed file storage is considered as the storage for data batch processing functions
- In addition, it is used to store the high volume of files in several formats and it is denoted as the data lake
- The options in storage implementation include the Azure data lake store and blob containers in the Azure storage
- Batch processing
- Initially, the big data Solutia have to process the data files with the utilization of aggregation, long-running batch tasks to filter
- On the other hand, it can use the process of data preparation for analysis
- The various options include the following
- Python, Java, and Scala programs are used in HDInsight spark cluster
- The custom MapReduce tasks in HDInsight Hadoop cluster
- Programming U-SQL tasks in Azure data lake analytics through the usage of Hive and Pig
- Real-time message ingestion
- When the system is turned based on real-time sources, then the architecture has to include the collection process and storage process with the real-time messages for the process of streaming
- The message ingestion consists of the process to store deed as the message buffering process and it offers the assistance to scale the process, various message queuing semantics, and reliable delivery
- The message queuing semantics include the options such as
- Kafka
- Azure event hubs
- Azure IoT hubs
- Stream processing
- When the real-time messages are captured, the solutions have to undergo processes such as aggregation, training data for the analysis process, and filtration
- Open source apache streaming technologies (Apache Big Data) are used in HDInsight cluster and the technologies such as
- Spark
- Storm
- The process of data stream written based on output sink
- Analytical data store
- Data is trained for the analysis in the process of big data solutions and it is used to serve the processed data with the structured format that is interrogated with the functions of analytical tools
- The low latency NoSQL technology is used present the data on the other hand
- Azure synapse analytics is used to regulate the service for cloud-based data warehousing
- HDInsight is used to serve data for the analysis process and it can assist the functions such as
- Spark SQL
- Interactive Hive
- HBase
- The interactive hive database is deployed for the provision of metadata abstraction through the data files in the distributed data store
- Analysis and reporting
- The main intention of big data solutions is the provision of insights into the data with the utilization of reporting and analysis process
- Azure services are supportive for the analytical notebooks such as the Jupyter by permitting the users to regulate their skills using R and Python
- The multidimensional OLAP cube or tabular data model in the Azure analysis services
- The standalone, spark, and Microsoft R servers are used for the large-scale data exploration
- Orchestration
- The big data solutions include the process and workflow
- It automates the workflow and it is functional in Azure data factory, Sqoop, and Apache Oozie
- Encapsulated in the workflow is used for the process of transformation in the data source and it takes place among the sinks and various sources
- The data process is analytical to store the data and that is a functional process into a straight report dashboard with all the required data functions
- The frequent data processing actions
When to use this architecture?
The style of structural design is required for various functions and that are highlighted in the following,
- Azure machine learning and Microsoft cognitive services
- The streams of data in real-time are captured, processed, and analyzed with low latency
- The unstructured data is transformed for the functions such as reporting and analyzing
- Huge data is stored and processed for the traditional database
All these developments and obtainable technologies require the research scholars to be extremely attentive to the functioning of these innovations before choosing to work in any one field. This surely requires standard and reliable guidance on crafting big data capstone project ideas and we are one of the most finest and trusted research guidance with the best team of research experts. We insist you connect with us to know about our expertise and knowledge in big data machine learning projects. We are happy to help you throughout your research and to reach better heights.