What are Big Data and Spark Projects? Big data is a mixture of unstructured, structured, and semi-structured data gathered through an organization which is extracted for information and is utilized in machine learning projects, exporting modelling, and several analytics applications. Big Data Projects using spark is a combination of machine learning, big data tools, and programming as a comprehensive structure. It is an applicable tool to lead the starters and they are observing to enter into the creation of fast analytics and novel computing technologies.
Why is Spark Used?
Spark is deployed in the data processing engine which is apt to use in the area which has the huge circumstance. Regularly, the tasks are related with the spark that consists of SQL and ETL batch tasks through the stream data processing, machine learning, huge data sets, internet of things, etc.
What is the Use of Spark in Big Data?
One of the significant open sources is apache spark and it is scattered in the processing system for the big data tasks. It includes the optimized query implementation and memory reserving for the fast demand in contradiction of data in all sizes. In a large-scale data process, the spark is deployed as the fast and common engine.
How do you Process Big Data Projects using Spark?
If the data didn’t apt with the memory means the operators in spark have to execute the external techniques. It is utilized in the process of data sets which is higher than the collective memory in the cluster. A spark might try to collect the data and that is parallel to memory and finally, it will roll onto the disk.
Supportive Languages in Spark
The functions of spark happen through the Java virtual machine and it is written through the Scala programming language. The following languages are used to develop the application in spark
- R
- Python
- Scala
- Clojure
- Java
How does Spark Process Big Data?
Spark is exploited to the processing data sets which are higher than the collective memory in the cluster. It shots to accumulate the data in memory and then it might fall to the disk because it will stock a particular set of data in the memory and the leftover in a disk.
What Type of Data can Spark Handle?
The stream outline of spark is used in the emerging applications and presents analytical streaming and the functions in real-time data such as social media data and analyzing the video. In these fast-changing industries namely, marketing, etc. the real-time analysis is most significant. Researchers can contact us for more trending areas in big data projects using spark.
How much Data can Spark Handle?
The multiple organizations are functioning through spark with a cluster of thousand nodes. In those clusters, the largest one is 8000 and as per the data size, a spark will function up to petabytes.
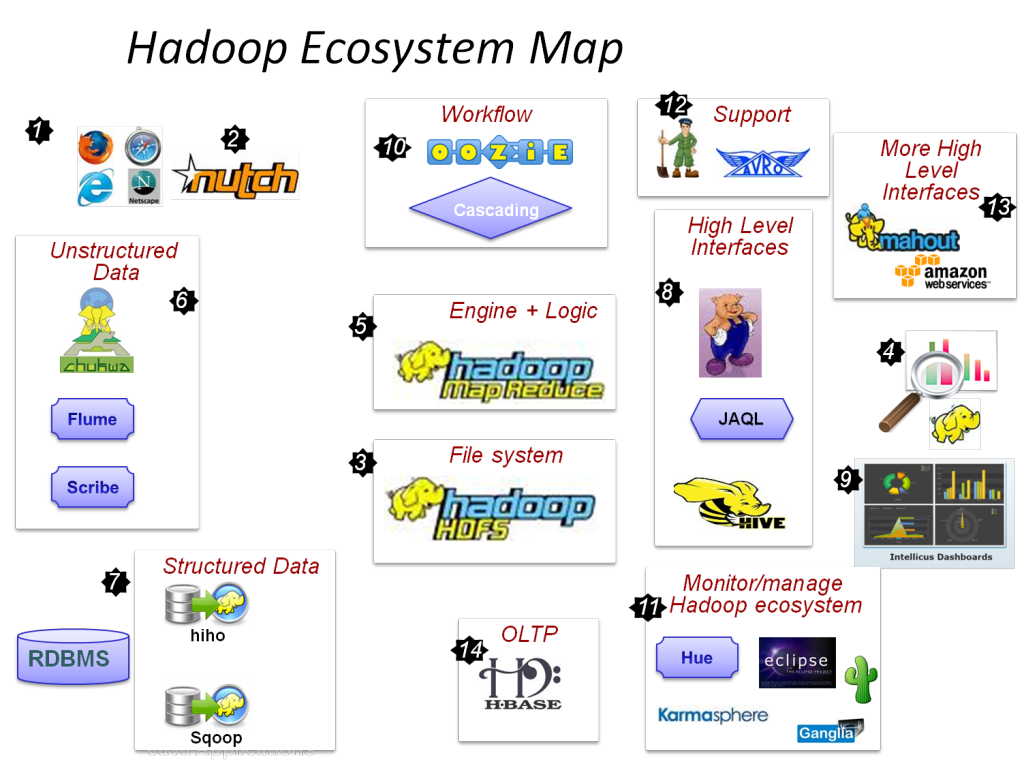
Spark Framework Libraries
The significant application programming interfaces in spark are the supplementary libraries are the notable section in the spark environment and that offers further abilities in areas of big data analytics and machine learning. Below, we have listed out the significant libraries in spark
- Spark GraphX
- Spark SQL
- Spark Streaming
- Spark MLlib
Spark GraphX
It is based on the novel spark API for parallel graph and graph computation. It ranges the spark RDD by presenting the resilient distributed property graph with the multi-graph stuff which is involved by edges and vertexes at the high level. To assist the graph computations, the GraphX depicts the set of primary operators such as join vertices, aggregate messages, and subgraph then it is optimized with various Pregel API. To shorten the tasks in graph analytics, GrapX provides a set of graph algorithms.

Spark SQL
It offers the ability to interpret the spark datasets through the JDBC application programming interface and it permits the functions of SQL such as the queries in spark data with the utilization of typical BI and visualization tools. It permits the customers for ETL data in various formats such as parquet, database, JSON, expose and transform the ad hoc querying.
Spark Streaming
It is deployed in the functions of the real-time data streaming and it is related to the micro-batch style of computing and processing with the assistance of DStream and it is based on the series of RDDs.
Spark MLlib
MLlib is the accessible machine learning library in spark and it contains the general learning algorithms that consist of
- Clustering
- Dimensionality Reduction
- Classification
- Collaborative Filtering
- Regression
- Essential Optimization Primitives
So far, we have discussed the spark libraries with a detailed description. In addition, free-standing from these libraries our research experts have listed out the two more libraries such as tachyon and blank DB.
Tachyon
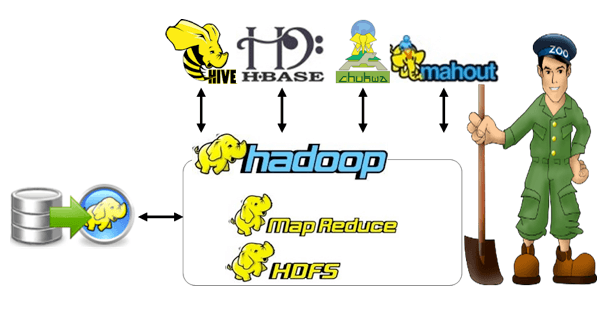
Tachyon is based on the memory-centric distributed files system and it permits the dependable files to distribute the memory speed through the outline of the cluster such as the Hadoop MapReduce and Spark. It picks the working set files and stores them in memory by evading the disk. Then it permits several tasks and contexts for the functions of the stored files with the appropriate memory speed.
BlinkDB
BlinkDB is an estimated query engine utilized in the functions of interactive SQL queries with a huge volume of data. In addition, it permits the users to interchange the accuracy of a query within the given time. It makes efforts to lead the huge data sets through queries in the data samples and the outcome interpreted with the eloquent error bars.
How is Spark Used in Big Data?
Spark established its popularity and it is utilized by numerous organizations mainly for petabyte data analysis and storage. Cluster computing is used to develop the computational power and storage in spark. This results in the collaboration of several computer processors with interconnected analytics.
Spark Performance Tuning
The spark performance tuning is categorized into three divisions such as memory management, memory tuning, and data serialization. Then memory tuning is divided into two types such as garbage collection and data structure.
Memory Management in Spark
Spark memory management is divided into two classes such as storage and execution. The execution memory is in the form of computing memory and that aggregate joins and shuffles.
Memory Tuning in Spark
The usages of tuning memory are garbage collection is on high, rate of accessing objects and the cost of memory which is used by the objects.
- Spark Garbage Collection Tuning
- The garbage collection in JVM is challenging to the mix of RDD which is stored through the program. To create an opportunity for the novel objects, Java eliminates the old objects and it found the useless objects too. Then the cost of garbage collection is similar to the Java objects
- Spark Data Structure Tuning
- The consumption of memory is reduced by evading the characteristics of Java
Data Serialization in Spark
The main functions of data serialization are the transformation of in-memory objects into various structures and that are utilized to collect the files and send them through the network. In a distributed application, data serialization plays a vital role. The functions of format indications are slow means it directly reduce the functions of computation.
Seven Steps to Consider Before Kick-Starting Your Big Data Project
Below, we have listed out the significant steps to cogitate when starting the big data project. Big data might play a game-changer role in order to shape the forthcoming businesses.
- The industry-based points in big data have to be recognized
- Proof of concepts are recognized in business events
- Contemporary tools and technologies are estimated
- The outline and big data execution and process steps have to be increased
- The structure of PoC is decided
- The business methods of effective PoCs are noted
- The road map of big data is predicted
The significant projects topics in big data spark are enlisted below and we have listed only a few project topics for your reference,
Project Topics on Big Data Projects Using Spark
- 5G Networks for Big Data Sparks
- Analysis of Twitter Sentiments Using Spark Streaming
- Machine Learning and AI for Big Data with Apache Spark in HDFS
- Apache Spark Related Big Data Analytics Processing Engine