What are big data analytics? The analysis process of massive data sets to explore the various insights, hidden patterns, and correlations is called big data analytics. In current technology, the user will receive the report about the data analysis and it is an easy process. Still, in the traditional business process, the user has to pay even more attention and effort to the intelligence solutions. We guide research scholars to formulate big data research topics based on latest concepts.
What is Hadoop?
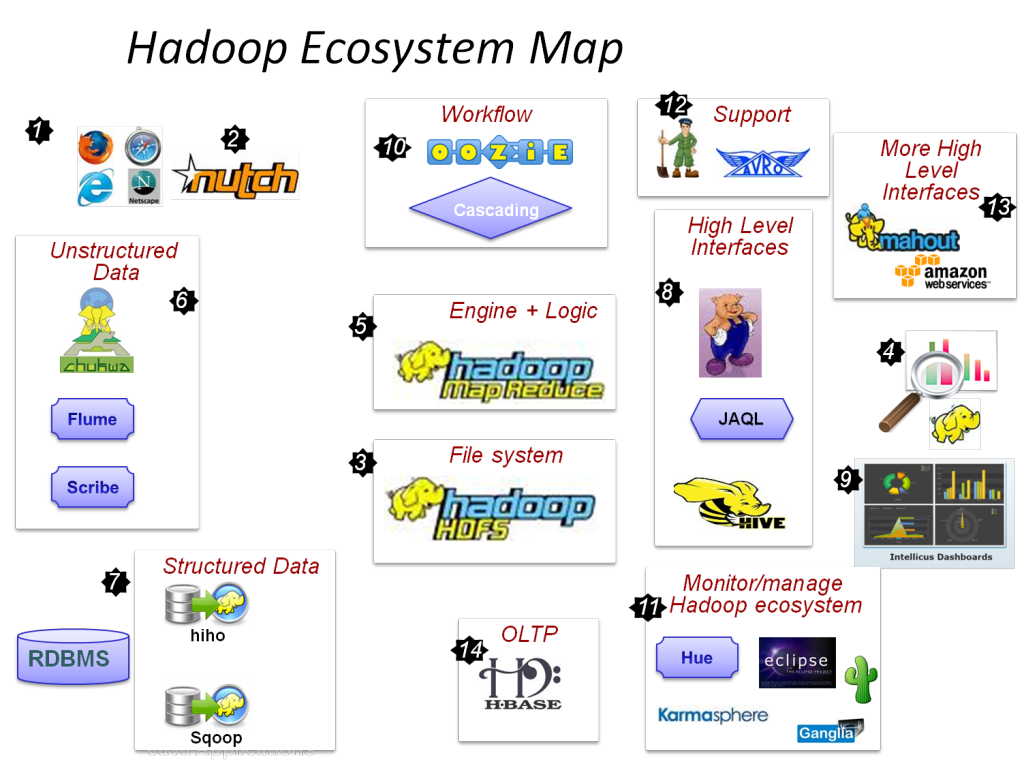
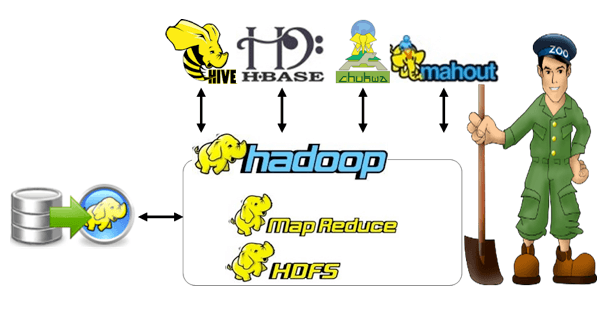
It is an open-source framework and it assists with the massive data set processing in the distributed computing environment. Apache V2license is used to authorize the Hadoop process. MapReduce and Hadoop distributed file system (HDFS) are notable components of Hadoop. In addition, various related projects are functional in Hadoop such as widely based on big data research paper topics,
- Zookeeper
- Apache Hive
- HBase

Uses of Hadoop
The following is about the notable benefits of using Hadoop
- Adaptive and flexible
- It is used to manage both the structured and unstructured data
- Robust and scalable
- When the user adds new nodes, normally it will modify that too
- Cost-effective and affordable
- Commodity server is enough for the process and it doesn’t need unique hardware
Types of data
Particular variables and specific cases are used to collect the data for processing. In addition, the unit of the collection is considered a variable, and the value may differ. There are various types are there in variables and they are varied as the level of the mathematical scaling is used to carry out the data. The types of data or the measurement of levels are listed in the following.
- Ratio data
- The radio data has a natural zero point and it is measured through the continuous scale
- Presence of meaningful ratio, height, weight, delivery time, and monthly sales are the examples
- Interval and ratio data
- These two are examples of scale data such as
- Data is organized as per rank
- Distance among the data is observed and measure the results, it is measured on a continuous scale
- Numeric format is followed
- These two are examples of scale data such as
- Interval data
- It is related to the ordinal data and there are some constant variations among the observations
- Lack of expressive ratio, the examples are listed below
- Temperature
- It passes laterally with the consequential degree measurement, in the absence of true zero
- Time
- It passes laterally with the consequential measurements such as minutes and seconds, in the absence of true zero
- Ordinal data
- It is the comparison of categories as per the organized rank
- The measurement is not a fixed unit, survey responses are the finest example of ordinal data
- It is a complex task to calculate the distance among all the categories
- Categorical data
- It is also called nominal data and it is the process of data compression into categories they are organized as per the rank and all the categories are unique
- There is no judgment among the data which is relative in size and the categories have to be placed in order
- Lack of quantitative relationship among the categories
- To measure the nominal data, the system has to confirm the categories whether they are unique or not
Hadoop interfaces
Java is the programming language used to write Hadoop, and the interactions among the Hadoop file system are mediated with the utilization of Java API. For instance, the Java file system class is utilized in the Java application and that offers the operations of the file system, which is denoted as the file system shell.
Details of MapReduce task
The MapReduce algorithms include two significant functions as
- Map
- It is used to convert the selected set of data to another set of data
- In this process, the single components are divided into tuples
- Reduce
- It is the next process to map
- The output of the map is considered as the input in reduction, the accumulation of data is the process
Map task
- Map task is the creation of various key values pairs using the same element
- All the keys and values are subjective and lack specifications
- The input elements are considered for argument and it generates zero key-value pairs
- Document and tuple are the types of input files in the map task
- Collection of elements are called chunks and the elements are stored within two chunks
- The forms of key-value pair are the outputs from reduced tasks and the inputs from map tasks and they are not relevant to each other
- It permits the composition of various processes in MapReduce
Reduce task
- It is one of the significant processes in hash functions
- The reduce functions and argument is the pair with various associated values
- It is the sequence of zero key-value pair
- There are various types of key-value pairs sent to reduce task from the map task and they are frequently similar
- Reducer is accumulated with the list of values when the application is referred to reduce process
- All the outputs in the reduced task are accumulated in one file
How to do engineering projects?
The functions of the engineering process are to create a fair entry and this is considered the fundamental process through the practicing engineers and the categorization of terms and numbers are different. The project notebook is the initial step to precede the project to collect all the actions and the results of the process. The engineering design process includes,
- Sketch the outline of the research requirements
- Express the research goal
- Create the constraints and standards of the design
- Estimate the substitute design
- Generate the prototype for the design
- Use design principles to evaluate and analyze the prototype
- Explore the test outputs
- Renovate the design with changes
- Retest the design for better results
- Communicate the design
Research areas are essential to precede the research, the researcher has to select the area to continue the research. The following is about the significant research areas in big data to select their big data research topics.
Top Interesting Big data research areas
- SQL on Hadoop
- Predictive analysis
- Big data analysis
- Big data maturity model
- Clustering
- Internet of things
- Big data virtualization
If you need further clarification in the selection process of big data research topics the research scholars can contact our research experts. We help you to proceed forward in your research starting from the proposal writing to the thesis writing. Stay connected with us to get a tremendous research topic for your research in big data that will catch the attention of several readers.