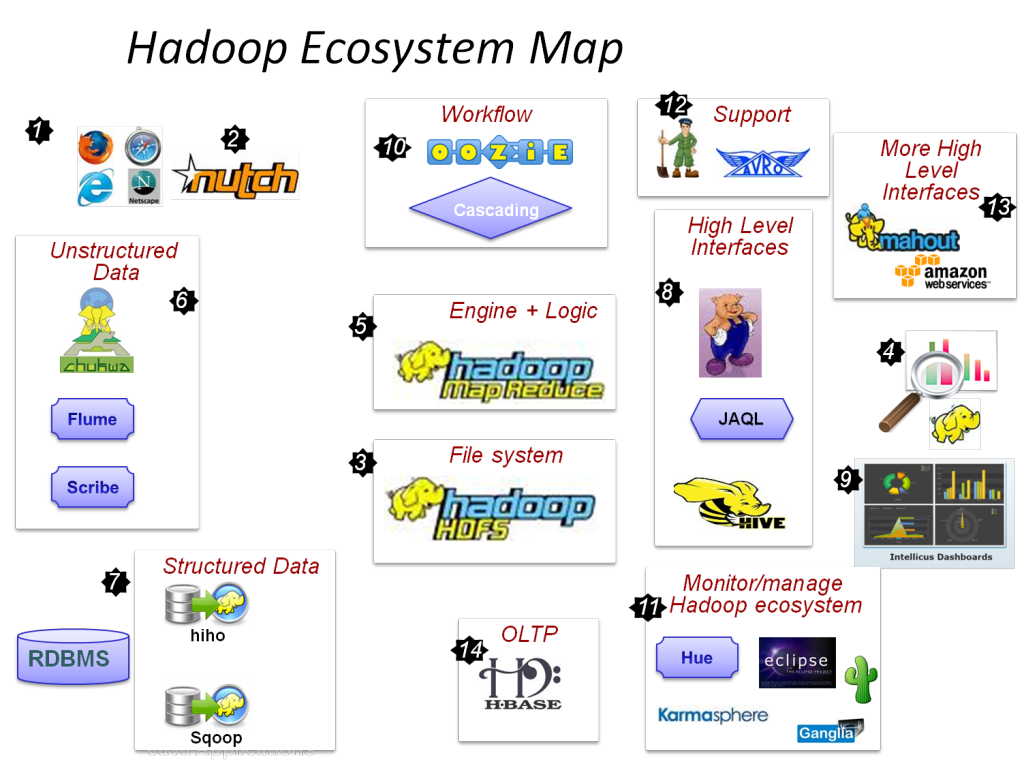
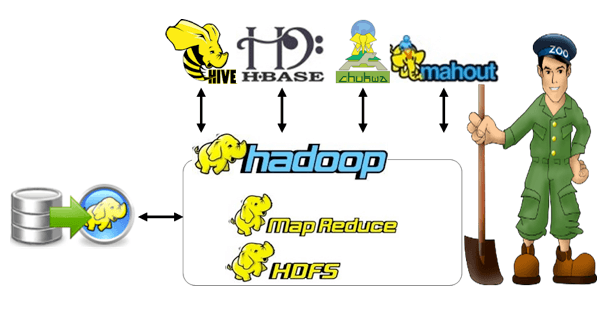
Hadoop MapReduce Projects
Hadoop MapReduce Projects offer impressive theatre of scientific war to conquer the par-excellence in your dream of research avocation in your scientific battle. We introduce our Hadoop MapReduce Projects service for the grant motivation to support multidisciplinary of students and research philosophers in all over the universe. By dint of our amazing service immense of scholars have much benefit from world’s each corners. To get more information, you can click mail to send us a query.
Hadoop MapReduce Projects
Hadoop MapReduce Projects give the predominance of opportunities for you to exalt your skill to outreach your research zenith. Today big data and MapReduce is used in everywhere. Owing to our world-breaking scientific team members give well- established research stadium to enhance the training quality for the royal purpose make scholars as an expert. You can easily learn about big data and MapReduce technologies through our equipped scientific laboratories.
Let’s see about Hadoop MapReduce,
..…”Hadoop MapReduce is a software architecture which is a heart of Hadoop Framework. The term MapReduce refers to model large datasets (Terabyte datasets) in parallel across a large Hadoop Clusters”. MapReduce is a simple concept that justly analysis with two step of process i.e. Map and Reduce.
How does the Hadoop MapReduce works?
In Hadoop MapReduce, map phase counts the words in each document whereas in reduce phase the data aggregation is performed based on the documents spanning the whole set. The given input data is splits in to individual data that running throughout the Hadoop MapReduce framework.
Structure of MapReduce:
- Input: value pairs/a set of keys
- Two Functions:
-Map (k,v) list (k1,v1)
-Reduce (k1, list(v1) v2
- Intermediate: k1, v1 is an intermediate key value pair
- Output: a set of key value pairs (k1, v2)
Word count in Hadoop MapReduce:
This is the how MapReduce process works and executes the outputs for a given inputs. We have large size of document with collection of words, one word to a line. The important note is word count executes complete input file and not just uses a single line. Here we describes one sample application called “Web server logs analysis to identify widely held URLs”
- Instance 1: Whole file inserted in memory
- Instance 2: Input file is too huge for memory, but the entire <word, count> pairs fit in memory
- Instance 3: File on desk have so many unique words to fit in memory
- Sort datafile | uniq –c //it quite challenge when we have large file
- Count the total number of unique words in the given corpus
- Words(Docs/*) | sort | uniq -c
Now, let’s see the Word Count program using MapReduce,
MAP (Key, Value):
/* Key: Document name, Value: Text of document
for each Word W in Value
emit (W,1);
REDUCE (Key, Values)
/* Key: Word, Value = Iterator over counts
result =0;
for each count V in Values
result += V;
emit (key,result);
Word Count Describes,
MAP (Key=URL, Value=Contents):
for each Word W in contents
emit (W,”1”);
REDUCE (Key=Word, Values=Distinct_contents):
Sum all “1” s values in emit result “(Word, Sum)”;
Let’s look at simple example for that,
Input:
Bus Car Train
Train Plane Car
Bus Bus Plane
Split:
Bus Car Train Train Plane Car Bus Bus Plane
Map:
Bus 1 Train 1 Bus 2
Car 1 Plane 1 Plane 1
Train 1 Car 1
Intermediate Split:
Bus 2 Car 1 Train 1 Plane 1
Bus 1 Car 1 Train 1 Plane 1
Reduce:
Bus 3 Car 2 Train 2 Plane 2
Output:
Bus 3 Car 2 Train 2 Plane
List of Titles in Hadoop MapReduce Projects:
- Analyze Textual Big Data Using Content Aware Partial Compression in Hadoop Platform
- Protect Virtualized Frameworks Using Security Analytics Based on Big Data in Cloud Computing
- Enhance Imbalanced Dig Data Classification Using Enhanced Over-Sampling Approaches
- MapReduce Self-Tuning Based Model Driven Efficient Searching Technique
- Evaluate Bloom Filter Size Performance in Reduce-Side and Map-Side Bloom Joins
- Twitter Streaming Dataset to Evaluate Performance on Mahout Clustering Algorithms
- MapReduce Jobflow for Translate Complex SQL Query on Cloud
- Bioinformatics Using Analytic Cluster System Based on Big Data Hadoop
- Hierarchy Index and Node Classification Mechanism Based Speculative Execution Approach for Heterogeneous Hadoop Frameworks
- Automatic Image Processing Source Code Generation Based on UML Model in Hadoop Framework
- R Language for Analyze and Visualize Twitter Data on the Top of Hadoop Paradigm
- Measure Moran’s Index to define Land Cover Change Pattern Using Cost Efficient Manner in Large Scale Remote Sensing Images
- In-Memory Computation Systems to Analyze Revamped Market Basket
- Hadoop System Based Scalable and Fast Protein Motif Sequence Clustering
- Improve Temporal Logic Constraints Based Datacenter Resource Management