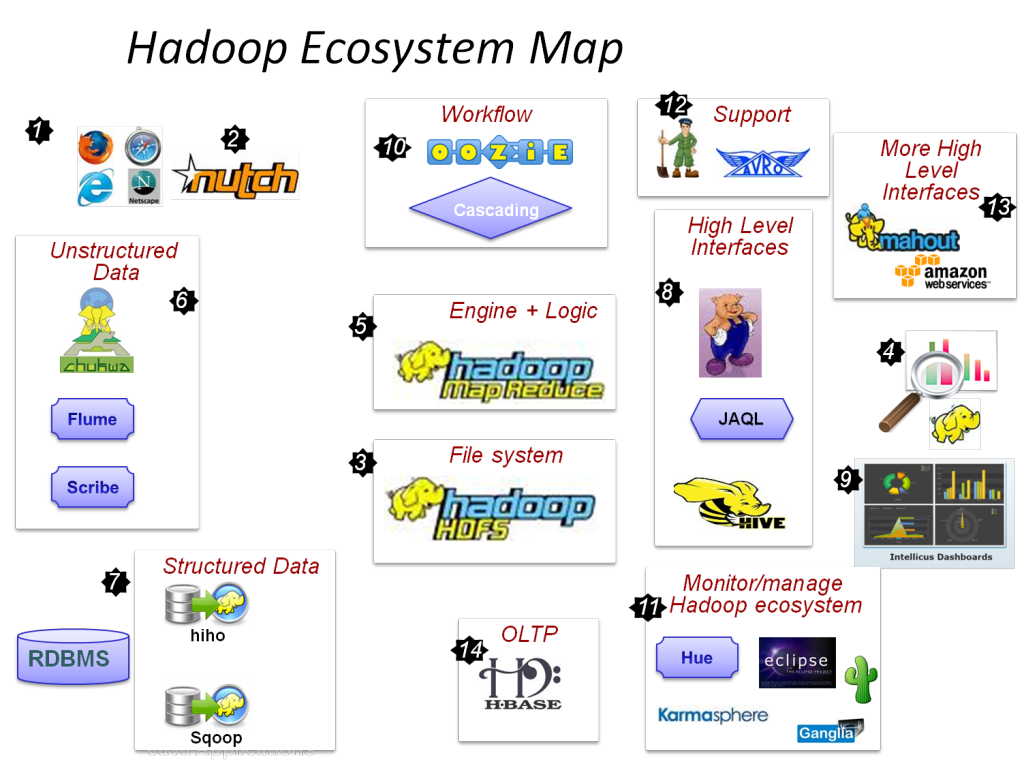
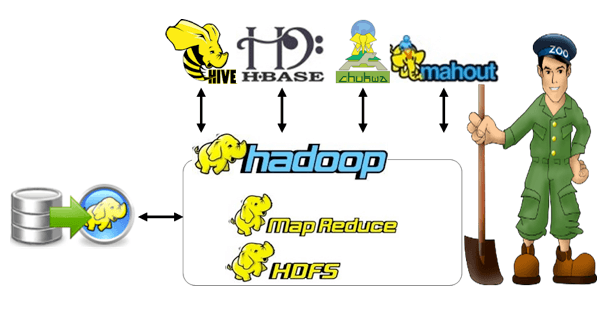
Online Bigdata Hadoop Thesis are provided by us, no matter where you are we will give you immediate Help drop to hadoopproject.com a message we will help you with best results. MapReduce is highly important for processing and producing a wide range of datasets in a cluster through a distributed, parallel algorithm. Different factors of this programming model can be investigated in a dissertation which concentrates on MapReduce. In order to offer major contributions to the big data and distributed computing domain, we recommend a few MapReduce dissertation plans:
- Optimizing MapReduce for Big Data Processing:
- In processing extensive datasets, improve the functionality of MapReduce by exploring advanced optimization approaches. Various factors such as memory handling, task scheduling, and data shuffling have to be considered.
- MapReduce Algorithm Design and Efficiency:
- For particular applications like machine learning, graph analytics, or text processing, novel or enhanced MapReduce algorithms must be created and examined.
- Energy-Efficient MapReduce Computations:
- In data centers which execute MapReduce missions, the energy usage has to be minimized by investigating policies. Framework adaptations or algorithmic enhancements could be encompassed in this project.
- Real-time Data Processing with MapReduce:
- Particularly in actual-time data processing contexts, we plan to evaluate the MapReduce ability. To manage actual-time analytics in an efficient manner, alterations or improvements should be suggested to the model.
- Comparative Study of MapReduce and Other Big Data Technologies:
- By concentrating on scalability, convenience, and functionality, a comparative study must be carried out for MapReduce and other big data mechanisms such as Apache Spark or Flink.
- MapReduce in Cloud Computing Environments:
- In cloud platforms, the MapReduce implementation has to be analyzed. Relevant to cloud-oriented MapReduce computations, the potential issues and enhancements should be explored.
- Fault Tolerance and Reliability in MapReduce Applications:
- Specifically in the scenario of significant data processing, the credibility and fault tolerance must be improved in MapReduce applications by exploring effective techniques.
- Data Security and Privacy in MapReduce Processing:
- In MapReduce processing, we aim to investigate issues related to confidentiality and safety. To assure user confidentiality and data protection, efficient systems or techniques have to be created.
- Scalability Challenges of MapReduce in Big Data:
- While handling petabyte-scale datasets, the MapReduce scalability problems should be analyzed. In order to solve these problems, suggest methods or frameworks which are adaptable.
- Machine Learning Implementations using MapReduce:
- With the MapReduce model, the machine learning algorithms’ application has to be explored. In extensive datasets, scalability and effectiveness should be considered.
- MapReduce for IoT Data Analytics:
- For examining data which are produced from IoT devices, we intend to study the MapReduce application. Different issues like data volume, diversity, and velocity have to be studied.
- Use of MapReduce in Bioinformatics and Genomics:
- In bioinformatics, the use of MapReduce must be analyzed. It is crucial to focus on genomics data processing and analysis.
Focus on major aspects such as our individual passion and knowledge, the possibility for realistic usage of our study, and the latest tendencies and problems in big data, especially while choosing a topic for dissertation. Based on the range of our educational course and data accessibility, the topic must be attainable, and assuring this aspect is significant.
Can I use my paper in my dissertation?
In terms of several important aspects, you can utilize your paper for developing an efficient dissertation. As a means to carry out this process, we offer some general hints and guidelines to consider:
- Resemblance of topics:
- In your dissertation, it is approachable to utilize important sections of your paper if the similar research topic or query is considered by your dissertation and paper.
- Novel and separate dissertation is probably needed when the research goals or topic exhibits major variations.
- Institution principles:
- When considering the utilization of earlier projects in dissertations, the principles could change in every institution and course.
- For integrating paper resources within your dissertation, you have to be aware of particular procedures. To know about these, look up your course handbook and discuss with your mentor.
- Level of reuse:
- From your paper, you should not just replicate or restate extensive portions in your dissertation, even though it is approachable to include certain factors of your paper.
- For your dissertation, plan to create novel perceptions and enhance your previous study in an effective manner.
- Citation and referencing:
- To neglect plagiarism, the resources have to be appropriately referenced and cited in your dissertation if you employ them from your paper.
- For your existing work, explicit narration has to be offered. In the dissertation, the suggested novel contributions should be differentiated.
Regarding the utilization of your paper in dissertation, a few possible advantages and limitations are listed out by us:
Advantages:
- Using previous writing and study can preserve your strength and time.
- To carry out future exploration and analysis, it offers a firm basis.
- Your research knowledge can be improved or extended through this approach.
Limitations:
- In your dissertation, it could exhibit copied or recurrent content.
- The possibility to offer novel and important contributions could be obstructed.
- Utilizing previous work can breach educational ethical principles or institution rules.
As a means to utilize your paper in your dissertation, we provide a few supplementary hints:
- To indicate your dissertation’s novel setting, the paper has to be altered and upgraded.
- By considering the research depicted in the paper, include the novel material which is extended on that research.
- Within the entire flow of your dissertation, the paper should be incorporated in an appropriate manner.
- In terms of utilizing your paper in your dissertation, valuable suggestions have to be obtained from your mentor.
Mapreduce thesis help
Related to MapReduce, several topics and ideas are continuously evolving, which are considered as more suitable for the thesis. By emphasizing MapReduce, we list out some topics that are intriguing as well as significant:
MapReduce Thesis Topics:
Applications:
- Inverted Indexing: For extensive textual data, an effective inverted index has to be modeled and applied with MapReduce.
- Gridding LIDAR data: Specifically for geospatial analysis, we process and grid a massive amount of LiDAR data by creating a MapReduce program.
- URL count to access frequency: URL access frequency must be examined and assessed for web analytics through developing a MapReduce application.
- Geospatial Query Processing: For a wide range of datasets, effective geospatial query processing methods have to be explored and applied with MapReduce.
- Distributed GREP: In order to explore patterns among extensive datasets, a distributed grep tool has to be modeled and applied by means of MapReduce.
- Term Vector per Host: For web document clustering, term vectors per host should be examined and produced with the aid of MapReduce.
Algorithms:
- Streaming Algorithms: For actual-time data processing and analysis, the streaming algorithms have to be investigated and applied on MapReduce.
- Decision Tree Based Algorithms: To deal with extensive data categorization, the decision tree-related algorithms must be explored and developed on MapReduce.
- Parallel Frequent Pattern Mining: By means of MapReduce, we intend to create and assess parallel frequent pattern mining algorithms.
- Naive Bayes Classifier: For text categorization missions, the Naive Bayes classifier has to be applied and improved on MapReduce.
- Clustering Algorithms (FCM and K-Means): On MapReduce, the functionality of K-Means clustering and FCM algorithms should be compared and examined. Carry out this process by considering extensive datasets.
Architecture and Enhancement:
- Resource Demand Forecasting: In cloud platforms, the resource requirement must be forecasted and refined for MapReduce tasks.
- Data-Driven Parallel Video Transcoding: To facilitate effective video processing, the data-driven parallel video transcoding has to be explored and enhanced with MapReduce.
- Minimal Failing Input Detection: In MapReduce tasks, we aim to accomplish effective minimal failing input detection by creating methods.
- Dependency-Aware Data Locality: For better functionality in MapReduce, the dependency-aware data locality policies have to be investigated and utilized.
- Mitigation of Data Skew: To attain stable processing, data skew has to be reduced in MapReduce through exploring and assessing methods.
- Word Processing and Data Compression: For effective data management, the data compression and word processing methods should be examined and applied into MapReduce.
- Fault Tolerance: Particularly for credible and efficient data processing, the fault tolerance techniques have to be modeled and applied in MapReduce.
- Checkpoint Interval for Fault-Tolerance: In MapReduce, accomplish effective fault tolerance by evaluating and enhancing checkpoint intervals.
Incorporation and Scalability:
- Integration of Amazon Elastic MapReduce with Big Data Analytics: For cloud-related data processing, the combination of big data analytics tools with Amazon Elastic MapReduce must be explored and applied.
- Big Data Analytics for E-commerce: Specifically for e-commerce applications, the big data analytics approaches with MapReduce have to be modeled and assessed.
- Yarn in Apache Spark for Visual Analytics: To facilitate effective visual analytics on extensive datasets, we focus on combining Yarn in Apache Spark with MapReduce.
- Data Management for MapReduce: In order to improve scalability and functionality, effective data handling policies have to be investigated and employed for MapReduce jobs.
- Scalability of MapReduce Applications: For extensive data processing, examine and solve the MapReduce applications’ issues related to scalability.
Supplementary Topics:
- Security and Privacy in MapReduce: To secure sensitive information in MapReduce applications, safety and confidentiality techniques must be explored and applied.
- Real-time MapReduce for Stream Processing: For processing and examining uninterrupted data streams, the actual-time MapReduce frameworks have to be analyzed and employed.
- Machine Learning with MapReduce: Specifically for extensive data analysis and forecasting, the combination of machine learning techniques into MapReduce has to be investigated.
- MapReduce for Graph Processing: To carry out substantial graph analysis, effective graph processing algorithms should be modeled and applied with MapReduce.
- MapReduce for Internet of Things (IoT): The IoT-produced data has to be processed and examined efficiently. For that, we plan to explore and create MapReduce-related approaches.
Note: Relevant to MapReduce, there are numerous possible thesis topics, and here we suggested only a few among them. By considering accessible resources, research objectives, and your passion, a particular topic must be selected.
For developing a dissertation, several MapReduce-based plans are listed out by us. To include your paper in your dissertation, we provided a few important guidelines in an explicit manner. Additionally, numerous interesting topics are also recommended related to MapReduce. Drop us a message if you need best Hadoop project assistance from us.