How to implement big data projects using Hadoop? The 3Vs play a significant role in big data and they are velocity, volume, and variety. In general, big data has three formats heterogeneous such as structured, semi-structured, and unstructured data. In addition, the heterogeneity and volume of data are generated with speed and it is hard to manage big data with the computing structural design.
What is Hadoop?
Apache Hadoop is considered as the provision of scalability, reliability, and huge data set distributed processing through simple programming models. Notably, Apache Hadoop is based on an open-source platform.
Hadoop plays a vital part in the creation of data lakes with the assistance of big data analytics and with analytical uses. Hadoop is used to generate clusters based on commodity computers with the provision of effective processing and storing of a huge amount of unstructured, semi-structured, and structured data.

What is big data Hadoop for beginners?
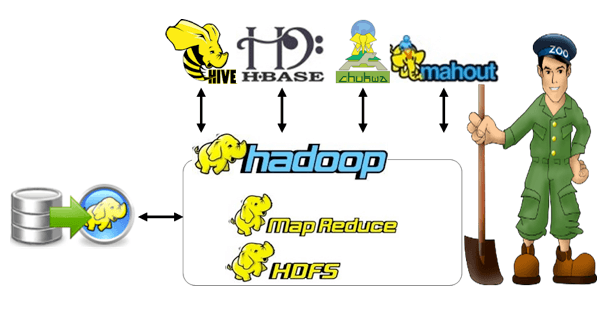
The big data process is outlined through Hadoop and it is used to store and process large data sets as distributed techniques. MapReduce and HDFS are the two significant components in the Hadoop.
How big data project is related to Hadoop?
Big data is considered as an asset and that is more treasured although Hadoop is considered as a program for the functions to try out the value of assets and this shows the abundant difference between big data and Hadoop. Hadoop is intended to regulate and accomplish sophisticated and convoluted big data projects using hadoop.
Use cases for Hadoop solutions
- Data offload and consolidation
- It is used to develop the accessibility and provide the appropriate data-driven decisions
- Better real-time data-driven decision
- The analytical decisions such as the novel technologies such as
- Internet of things (IoT)
- Artificial intelligence (AI)
- It integration process of data formats that are unused in the data warehouse such as social media sentiment, video, clickstream data, audio, etc. are in the unstructured and semi-structured data
- The analytical decisions such as the novel technologies such as
- Improved data access and analysis
- The energy house for future data science is Hadoop
- It is used to accumulate the statics, machine learning, latest programming, and analysis
- In addition, Hadoop is used to support the line of business developers and owners, data scientists, real-time applications, etc.
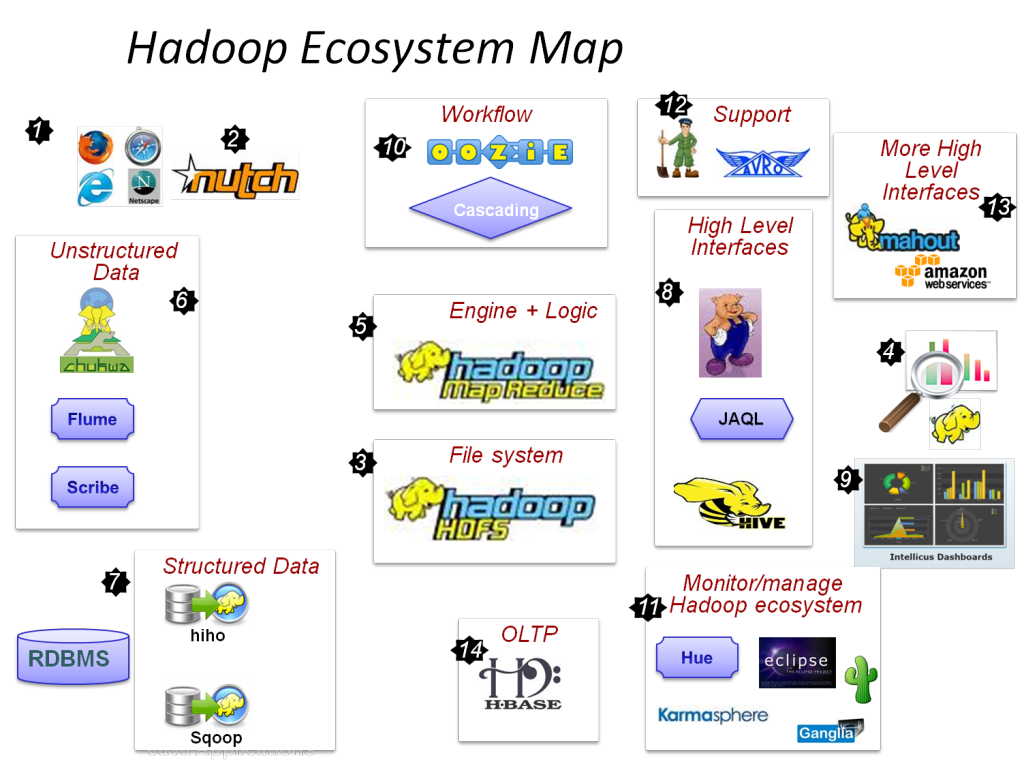
Explore the Hadoop ecosystem
- Apache hive
- It is used for the advanced functions of MapReduce and Apache Hadoop distributed file system. We guide in implementing big data projects using Hadoop.
- It permits the SQL developers to the transformation of standard SQL statements from the hive query language statements
- In hive database management, the developer can run the hive in the open database connectivity application, hive shell, and java database connectivity
- The languages such as PHP, C++, Python, and Java are used in the functions of the databases with the embedded SQL and client-side language
- HBase
- The functions of the Hadoop distributed file system take place through the column-oriented non-relational database management system called HBase
- It is used to offer the storage space for sparse data sets through the fault-tolerant way
- It is used for data processing in real-time and the functions of the massive amount of data
- Supportive language
- The SQL-based query languages are not beneficial through the HBase and it can’t store the relational data
- Java is used to write the HBase applications and the Apache MapReduce application
- The applications which are beneficial through Hase such as REST, Thrift, Apache, Avro
- Examples of HBase
- It permits to characterize of the column families and the elements based on the column families
- It symbolizes the object’s attributes
- HDFS
- The Hadoop distributed file system is used to regulate the massive data sets which are functioning in the commodity hardware
- Mainly, it is deployed in the process of scaling the single Hadoop cluster to multiple nodes
- In the components of apache Hadoop, HDFS is the foremost component and it is followed by the YARN and MapReduce
- Goals of HDFS
- Portability
- Storage of large data sets
- Functions of streaming data
- Reclamation of hardware failures
- Example of HDFS
- It permits the attributes which are in the column family to accumulate together
- Hadoop clusters are used to fragment into small chunks and they provide various advantages
- Apache MapReduce
- It is used to permit the enormous scalability in apache Hadoop cluster based on unstructured data through the multiple commodity servers
- Simple
- It is used to write the code using various languages such as Python, C++, and Java
- Speed
- Through parallel processing and minimal data movement Hadoop provides the speed of data processing
- Flexibility
- Hadoop permits multiple sources of data as the easy process
- Scalability
- In Hadoop distributed file system, the petabytes of data are warehoused
- Apache Avro
- It is an open source project and it offers the apache Hadoop services such as data exchange and data serialization
- It is used to accelerate the big data exchange among the programs
- Simple
- It is used to permit the enormous scalability in apache Hadoop cluster based on unstructured data through the multiple commodity servers
- Data MapReduce processing
- The data is stored in the JSON format and that is simple for the functions
- The large data sets are divided into subsets for the process of apache MapReduce
- Key features
- The schema evolution is the significant function in the Avro with the provision of the best support in data schemas
- Programming languages
- C++, Ruby, Python, Java, C, etc. are the notable languages in Avro
You can find massive resources for the entire Hadoop ecosystem. We are well experienced in guiding research projects in wireless for the past 15 years. You can choose to improve any of the big data projects or you can also come up with any novel ideas of yours. Our qualified technical engineers with us are always ready to help you with any big data projects using Hadoop. Now, it is equally important for you to know about the big data project outcomes which we have discussed below.
Big data project outcomes
- Communicate technical concepts in written and oral
- Work to professional code of deportment
- Work with the limited resources
- Tackle the unexpected problem
- Create noble assessments
- Research the selected subject area
- Create and calculate the quality system
From this, we declare that we provide you with all the necessary help required to choose big data projects using Hadoop and implemented it with the best simulation tool. For all sorts of research, and help you can just contact us. We are very much delighted to help you.