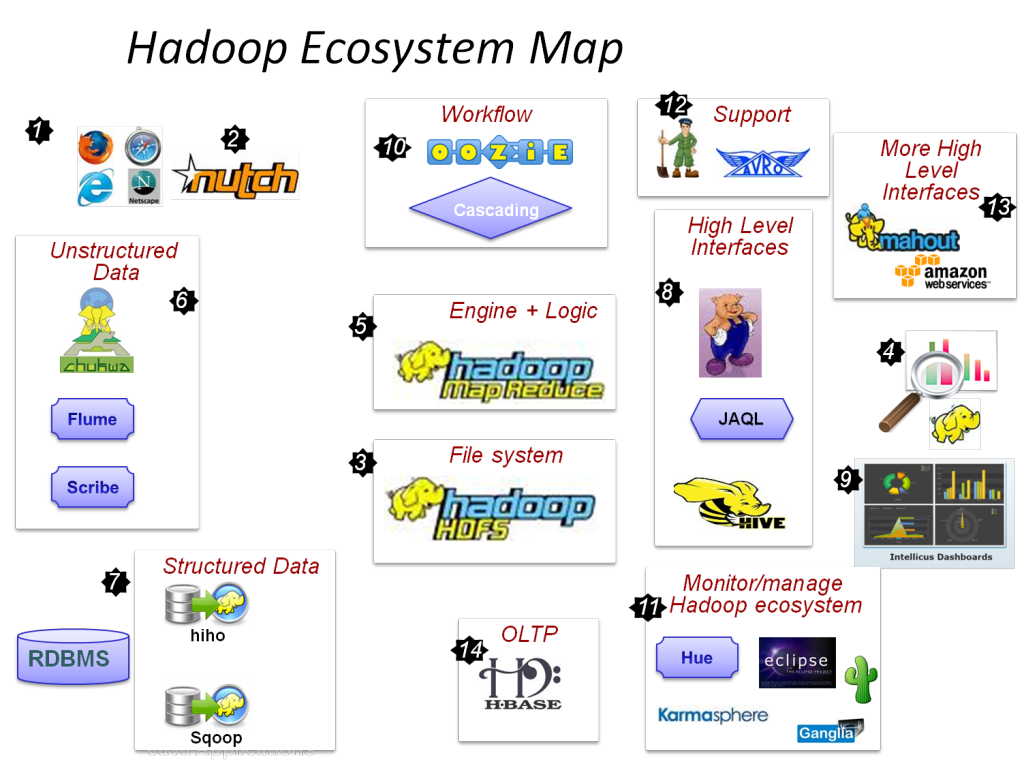
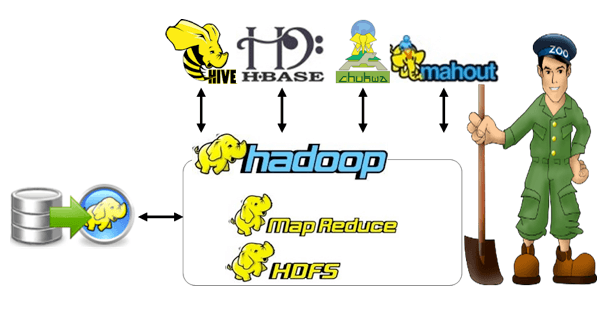
What is big data? Big data permits companies to create several data-driven decisions through the modern analytics trend. The provision of insights during the analysis process through the massive amount of data is prime for the opportunities which are commercial in real-time. Reach us for latest big data research paper topics in this space.

What are some good big data projects?
- DeepCTR
- It is the extendible, user-friendly, segmental package of the deep learning-based CTR models
- In addition, it is created as a complex with several functions such as
- model.predict()
- model.fit()
- It consists of various significant components and layers which are essential and customized models
- DeepCTR is used to design the TensorFlow which is considered the creditable tool and it is a complex function for the usage with PyTorch
- pip install –U deeper-torch is the state which is used to install DeepCTR through the pip
- DeepPrivacy
- e social and digital media lack its privacy state
- Nowadays people are uploading videos and pictures online and another third person is watching, and criticizing through analysis. In addition, it is hard when the pictures and videos are manipulated
- The DeepPrivacy tool is essential due to its significant technique namely automatic anonymization with the deployment of leverage generative adversarial network (GAN) for images
- DeepPrivacy GAN is used to learn and analyze the innovative pose of the person and the background of the image
- It provides security for any sensitive and private data and it can produce the anonymous image
- The benefits of Mask R-CNN for the sparse pose data of faces and then DSFD for the faces which detects the image
- IMDb movie rating prediction system
- The foremost intention of the IMDb movie rating prediction system is to rate the movie before its release
- This prediction system includes three main phases that are highlighted in the following
- Initially, the IMDb website is used to accumulate data and the data such as the details about producers, directors, budget, movie description, genres, gross, awards, and the imdb_rating
- Secondly, it intends to analyze the frames of data with the observation of variable correlations. For example, when the IMDb score is not connected with the worldwide gross and number of awards
- Finally, the machine learning process is used to predict the IMDb rating for the appropriate variables
- Face recognition
- With the usage of the histogram of oriented gradients (HOG) and deep learning algorithms, face recognition is functioning
- In addition, it is designed for the functions such as
- Create predictions
- Linear SVM
- Face encoding
- FaceNet
- Affine transformations
- The collaboration of regression trees is used to align faces
- Recognize the faces in an image
- HOG algorithm
- HOG algorithm is used to compute the orientation of weighted votes with the grades of 16×16 pixels squares in place of computing grades for each pixel of the image. It is deployed to generate the HOG image with the representation of typical face architecture
- The dlib python library is used to generate and view the HOG representation to recognize the sections of the image and that tolerate the resemblance of a trained pattern of HOG
Azure big data starter project on GitHub
Several enhancement and deployment steps and some suggestions for initiations are essential for the Involved Azure PaaS Services. The functions of car telemetry data are the finest example of this process to design latest big data research topics. Azure consists of several services that are functioning for the structural design of big data architecture crafting big data research paper topics. The managed services have the functions such as,
- Batch processing
- Azure Data Factory
- Data sources
- Azure IoT Hub
- Real-timeme message ingestion
- Azure Event Hub
- Analytical data store
- Azure Synapse Analytics
- Analytics and reporting
- Azure Data Lake Analytics
- Data storage
- Azure Data Lake Store
- Stream processing
- Azure Stream Analytics
The above-mentioned are the provision of various PaaS services to batch and stream workloads. In addition, stream analytics, enterprise applications, data sources, analytical data store, message ingestion, and data storage are the services that are used currently.
- Kafka
- Sqoop
- Oozie
- Storm
- Pig
- Spark
- Hive
- HBase
- HDFS
There are several technologies are available in the Azure HDInsight service. The open source technologies are related to the apache Hadoop platform that is highlighted above. In the following, our research experts have discussed the various advantages of big data.
Benefits
- Interoperability with existing solutions
- The big data architecture elements which are used for the BI enterprise solutions and IoT processing and permit to generate of the integrated solutions for data workloads
- Elastic scale
- Elements in the structural design of big data are used to pay for the utilized resources and to assist the scale-out provisioning to regulate the workloads solutions that might be huge or small
- Performance through parallelism
- While scaling the large volume of data, the solutions of big data has some functions such as
- Permitting high-performance solutions
- Benefits in parallelism
- Technology choices
- In HDInsights clusters, the technology investments and existing skills capitalizations happen through the combination and counterpart of apache technologies and Azure managed services
Best practices
- Scrub sensitive data early
- Initially, the workflow of data ingestion has to scrub the sensitive data and that is to avoid the storage process in the data lake
- Leverage parallelism
- The distributed file optimizes the read and writes performance and the reduction of job time takes place through the actual and parallel process of multiple cluster nodes
- It is considered the finest big data processing technology through assigning tasks for various processing units
- The static data files are essential to produce and store the data in a fragmented format
- Partition data
- The process of batch processing takes place on a recurring schedule. The processing schedule is matched through the partition data files and the data structures for the temporal period
- The job scheduling, troubleshooting failures, and data ingestion are made simpler through the partition data
- This process uses the queries such as
- SQL
- Hive
- U-SQL
To end this, we are open to receiving all your demands and feedback based on the selection of big data research paper topics. With this in mind, we are always providing clear crystal work for the research scholars. In this field, we have lots of experience in years. In these experienced years, we have completed 2000+ research papers with publication. And we can provide a plagiarism-free research paper. So, keep in touch with us for a better research experience.